Corrija o erro "Não foi possível ler o sitemap"
Pare de lutar com erros do Google Search Console. Indexe seu sitemap corretamente e observe o crescimento do seu tráfego orgânico.
Experimente IndexJump grátis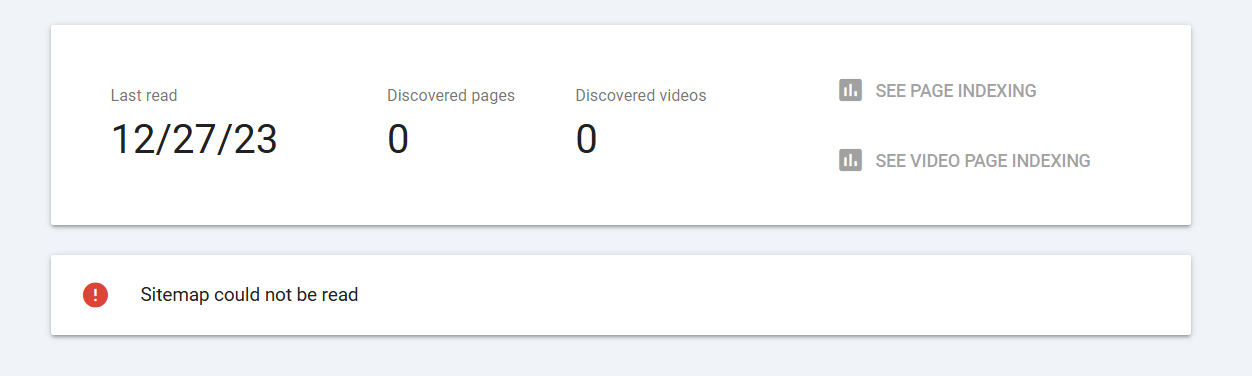
Pare de lutar com erros do Google Search Console. Indexe seu sitemap corretamente e observe o crescimento do seu tráfego orgânico.
Experimente IndexJump grátisDescubra nossa experiência em resolver problemas de sitemap e indexação
When a sitemap cannot be read by search engines, it interrupts a vital communication channel between your Shopify store and the crawlers that index its pages. For ecommerce sites, this gap can translate into slower discovery of new products, updates to inventory, and changes in pricing or promotions. In practice, an unreadable sitemap can lead to delayed indexing, missed opportunities for product visibility, and a fragmented crawl of your catalog. While Shopify inherently manages many technical duties, the sitemap is still a critical artifact that informs search engines about which pages to prioritize and how often they should revisit them, especially for large catalogs with frequent updates.
The impact on visibility is not merely theoretical. Search engines rely on sitemaps to understand site structure, confirm canonical versions of pages, and detect changes in content. When Shopify users encounter sitemap read failures, search engines may fall back to discovering pages through internal linking or external signals, which can be slower or less reliable. For merchants running promotions, seasonal launches, or inventory flushes, even a short window of unreadable sitemap can delay indexing of new or updated URLs, reducing the chance that customers see those changes in search results promptly.
From a crawl-efficiency perspective, an unreadable sitemap places more burden on the crawl budget. If search engines struggle to parse the sitemap, they may deprioritize or skip certain sections of the catalog, particularly category pages or new product entries. This behavior is especially consequential for stores with hundreds or thousands of SKUs, where timely indexing of updates is essential to sustaining organic traffic and conversion rates. The practical takeaway for Shopify store owners is clear: ensuring a readable sitemap is an investment in reliable content discoverability and consistent organic performance.
For merchants who rely on Shopify as a performance lever, the sitemap is part of a broader SEO system. It complements internal linking, product schema, and structured data signals. When the sitemap reads correctly, it helps engines map product pages, collections, blog content, and policy pages into a coherent index, supporting more efficient crawls and timely indexing. Conversely, unreadable sitemaps can create blind spots in the index, making it harder for potential customers to locate product listings, filter results, or access new content. This dynamic is particularly critical for stores with rapid inventory changes or frequent price adjustments, where accuracy and timeliness in indexing correlate with revenue opportunities.
From a user-experience viewpoint, an readable sitemap often correlates with better site health signals. While users do not directly interact with a sitemap, the underlying indexing health influences how quickly product pages appear in search results and how accurately rich results (like product snippets) can be shown. In short, a readable sitemap supports both discovery and trust: it helps search engines surface the most relevant and up-to-date content to shoppers while reinforcing the perceived reliability of the storefront.
Key considerations for Shopify merchants include understanding how sitemap issues arise, recognizing the signs of a problem, and preparing a workflow for quick remediation. This multi-part guide walks through practical steps that align with industry best practices and platform-specific nuances, including how to verify the sitemap URL, test accessibility, validate XML, and ensure that crawlers can reach the file without hindrance. The objective is to establish a repeatable process that minimizes downtime, keeps indexing aligned with product updates, and preserves overall search visibility.
As you progress through this series, you’ll gain a practical framework for diagnosing unreadable sitemap scenarios, adjusting your Shopify configurations, and safeguarding ongoing visibility. For broader context on how search engines handle sitemaps and the recommended practices, refer to established guidelines from authoritative sources such as Google’s sitemap guidelines.
The following sections of this guide will zoom in on practical actions you can take if you encounter a sitemap that cannot be read. While the problem can stem from several root causes, a disciplined verification approach helps you isolate the issue quickly and apply the right fix without disrupting live commerce. The early part of this article sets the expectations: you will learn how to locate the official sitemap, assess accessibility, validate structure, and prepare for re-submission to search engines once the file is readable again.
In Shopify environments, several common scenarios can trigger unreadable sitemap states. These include misconfigured robots.txt rules that inadvertently block the sitemap URL, temporary hosting issues, or runtime errors in dynamic sitemap generation during heavy traffic. While these situations are often resolvable with targeted adjustments, they still warrant a structured diagnostic approach to prevent recurrence. The rest of Part 1 outlines the conceptual impact, while Part 2 will guide you through locating and verifying the sitemap URL within Shopify’s settings, ensuring you reference the correct path for crawling and submission.
Understanding the broader ecosystem helps you contextualize the problem. Sitemaps are not isolated artifacts; they are part of a coordinated SEO strategy that includes robots exclusions, canonical signals, and server configurations. Ensuring their readability is not only about fixing a file but also about preserving the integrity of how your store communicates with search engines. This approach reduces the risk of indexing gaps during campaigns, launches, or inventory restructures. In Part 2, you’ll learn how to locate the sitemap URL within Shopify, verify you’re referencing the correct path, and begin the process of testing access — the first concrete steps toward remediation.
Building on Part 1’s emphasis on a readable sitemap, the next practical step is identifying the exact sitemap location you should reference for crawling and submission. For Shopify stores, the canonical sitemap is hosted at a predictable path, but validation requires confirming the correct domain and URL variant in use. Begin with a concise verification process that centers on the primary domain customers see and the version used by search engines. This ensures you’re not chasing a stale or blocked sitemap URL that could contribute to the error message about a sitemap that could not be read.
The official sitemap location is usually exposed as a /sitemap.xml resource on the primary domain. In many Shopify setups, you may encounter two plausible paths:
To determine which variant search engines expect, check the site’s robots.txt, which commonly includes a line like "Sitemap: https://yourdomain.com/sitemap.xml". If the robots.txt points to a different host or path, align your submission with that directive. You can inspect robots.txt directly by visiting https://yourdomain.com/robots.txt. If you manage multiple domains or redirects, confirm that the canonical sitemap is the one available on the primary domain used for indexing. For authoritative guidance on sitemap structure and submission, refer to Google's sitemap guidelines.
Once you identify the likely sitemap URL, perform a quick accessibility check in a browser or via a lightweight HTTP request. A successful discovery is a 200 OK response with a content type suitable for XML, typically text/xml or application/xml. If you encounter redirects, 404s, or 403s, you’re observing the same access symptoms that can cause a sitemap read failure. Documenting the exact URL variant that returns a readable response helps your remediation workflow stay aligned across teams and tools.
In Shopify environments, a frequent signal of correctness is the presence of a sitemap index at /sitemap.xml that links to sub-sitemaps for products, collections, pages, and blog posts. This hierarchical structure is normal and expected; it enables search engines to crawl large catalogs efficiently. If your sitemap.xml resolves but the content appears incomplete or missing expected sections, move to the next verification steps to confirm the integrity of the underlying files and their access rights.
Attach a simple checklist to your process for sustaining this step over time. Record the confirmed sitemap URL, the domain variant used for indexing, and the timestamp of the last test. If you rely on a content delivery network (CDN) or caching layer, note any recent changes that could affect availability. This disciplined documentation helps prevent future occurrences of the same unreadable sitemap scenario and supports faster re-indexing after fixes. For teams seeking continuous improvements, our SEO Services can help establish automated health checks and alerting for sitemap health on Shopify stores.
In cases where the sitemap URL is not easily reachable from hosting infrastructure, or if the store uses a dynamic generation path that occasionally alters the URL, plan a fallback approach. Maintain a canonical reference in your internal SOPs and ensure that any app or theme changes do not unintentionally block sitemap access. After confirming the sitemap URL, the natural next step is to verify accessibility and HTTP status in a structured way, which Part 3 will cover in detail. This ensures you’re not only finding the right file but also ensuring it is reliably readable by crawlers.
After you locate the sitemap URL, the next crucial step is to verify accessibility at the server level. Start with a straightforward check using a browser or a lightweight HTTP header request to determine the status code returned by the sitemap URL. A clean read typically surfaces a 200 OK with an XML content type. If you encounter redirects, 403, 404, or 500-series errors, you’ve identified the layer responsible for the unreadable sitemap and can target remediation accordingly.
To perform a more repeatable test, use a header-only request that fetches only the status line. For example, a curl command such as curl -I 'https://yourdomain.com/sitemap.xml' or curl -I 'https://yourdomain.com/sitemap.xml' -L can reveal whether the sitemap is reachable and if redirects are involved. If the final URL after redirects is a different host or path, ensure that this final URL matches what search engines are supposed to crawl for indexing. Consistency between the URL you submit and the URL your robots.txt and Google Search Console expect is essential to avoid confusion for crawlers.
Redirects warrant special attention. A chain of redirects can cause crawl inefficiencies or timeouts, especially for large catalogs where the sitemap is referenced by multiple signals. If you observe a 301/302 redirect, verify that the destination URL remains under the same primary domain and uses the same protocol (https). A mismatch in protocol or cross-domain redirects may confuse crawlers and hinder timely indexing. If redirects are necessary due to domain changes or CDN routing, update your robots.txt and sitemap references to reflect the canonical path that you want crawlers to use.
In cases where the server responds with 403 Forbidden, 404 Not Found, or 500 Internal Server Error, you must diagnose permission and server health issues. A 403 can indicate IP-based access controls, user-agent restrictions, or misconfigured security rules that block crawlers. A 404 suggests the sitemap was moved or removed without updating the public references. A 500-level error signals a transient server problem or misconfiguration on the hosting stack. Record the exact status code, the time, and any recent changes to hosting, edge caching, or security plugins so you can reproduce and verify fixes later.
Caching layers and content delivery networks can mask underlying accessibility problems. A user might still receive a cached 200 response even if the origin server is returning errors. To avoid this, purge relevant cache layers after making changes to the sitemap path or server configuration, and re-test directly against the origin URL. If you rely on a CDN, ensure the origin pull path aligns with the URL you intend search engines to crawl. This practice helps prevent stale or blocked sitemap responses from misleading crawlers.
Another layer to consider is how the sitemap is served in relation to robots.txt. If robots.txt blocks the sitemap URL, search engines will not fetch it even if the URL is technically reachable. Confirm that the robots.txt file located on your domain does not disallow the sitemap path and that there is a clear directive like Sitemap: https://yourdomain.com/sitemap.xml unless you have a platform-specific reason to manage the path differently. If you find such blocks, work with your hosting or platform provider to align robots rules with the intended crawl strategy.
As you verify accessibility, document each result with timestamped notes and corresponding URL variants. This creates a traceable remediation trail, making it easier to coordinate with developers, your SEO team, or an agency. For ongoing prevention, consider implementing automated health checks that periodically validate the sitemap URL, status codes, and content-type. Our team offers automated monitoring as part of our SEO services, which can be integrated with Shopify-specific configurations for quicker detection and response, see SEO Services.
In Part 4, you’ll translate these accessibility findings into concrete validation steps for the XML structure, ensuring the sitemap’s syntax and content align with best practices. Google’s guidelines remain a reliable reference point for structure and submission expectations, available here: Google's sitemap guidelines.
Key practical takeaways from this section include: verify a clean 200 response or acceptable redirects, identify and fix blocking or misrouting through server and CDN configurations, and ensure robots.txt aligns with the sitemap URL you intend to expose to crawlers. By maintaining consistent URL references and robust access tests, you reduce the risk of sitemap readability failures that could similarly affect Shopify stores with sizable inventories and frequent updates.
XML validity is the backbone of a readable sitemap. For Shopify stores, even small syntax errors can render the entire sitemap unreadable by crawlers, triggering the frustration around a sitemap could not be read and delaying indexing of newly added products, collections, or content. A disciplined validation process not only catches mistakes early but also strengthens long-term crawl reliability. This section translates the theory of a readable sitemap into concrete, platform-aware actions you can implement with confidence.
Begin with the fundamentals of XML syntax. Ensure every tag is properly opened and closed, attributes use consistent quotation marks, and there are no stray characters outside the XML declaration. A well-formed sitemap starts with an XML declaration such as <?xml version="1.0" encoding="UTF-8"?> and follows the hierarchical rules of the Sitemap Protocol. Even seemingly tiny errors, like missing end tags or an unescaped ampersand, can invalidate parsing by search engines and trigger read failures.
To operationalize this, employ an XML validator as part of your workflow. Copy the sitemap content into a validator tool and review the reported issues. Focus first on structural problems: unbalanced elements, incorrect nesting, and syntax that violates XML rules. After resolving these, re-validate to confirm that the file is now well-formed. This step is essential before you assess encoding and content accuracy, because a syntactically invalid file cannot be parsed by the engine even if the data appears correct at a glance.
Beyond well-formed XML, encoding consistency matters. UTF-8 is the industry standard for sitemaps and ensures compatibility with the broadest range of crawlers and content characters. If your store uses non-ASCII characters (for example in product names or URLs), confirm that the encoding declaration matches the actual file encoding and avoid mixed encodings within the same sitemap. Mismatches often surface as garbled characters or parsing errors in certain sections, which can cause partial indexing failures even when most of the sitemap is correct.
Next, validate the structural conventions of the Sitemap Protocol. Shopify sitemaps typically use a sitemapindex that links to sub-sitemaps for products, collections, pages, and blog posts. Each entry must include a <loc> tag with a fully qualified URL and, optionally, a <lastmod> tag formatted in ISO 8601. Validate that each URL uses the same canonical domain and protocol and that there are no trailing spaces or line breaks within tags. Inconsistent URL schemes or mismatched domains can confuse crawlers and lead to incomplete indexing even when the XML is otherwise valid.
A practical approach is to run a targeted validation pass on a sample subset of URLs before validating the entire file. This helps you identify domain or path-level issues that could cause broader reading problems. For Shopify stores with large catalogs, ensure that dynamic URL generation does not introduce malformed slugs or spaces that would render a URL invalid. If you maintain multiple sub-sitemaps, confirm that the linking structure in the sitemapindex is accurate and that no orphaned entries exist that point to non-existent resources.
Additionally, watch for encoding anomalies in the URL values themselves. Special characters should be percent-encoded where required, and you should avoid raw characters that break XML parsing. A clean, consistent encoding policy reduces the risk of misinterpretation by search engines during crawl operations.
After achieving a clean, well-formed XML file, proceed to content validation. Confirm that all listed URLs are live, accessible, and on the correct domain with the expected protocol. This ensures there is no mismatch between what the sitemap declares and what search engines fetch. If you use a staging domain or alternate versions for testing, clearly separate those from your production sitemap to prevent accidental indexing of test content.
To support ongoing quality, couple XML validation with automated health checks. A periodic pass that validates syntax, encoding, and structural conformance helps catch regressions caused by theme updates, app integrations, or CDN reconfigurations. If you would like expert assistance in maintaining a robust sitemap workflow within Shopify, our SEO Services can tailor automated validation and alerting to your store scale and update cadence.
Key actions to take from this part stop include:
For additional context on how search engines interpret and validate sitemaps, refer to Google's official guidelines at Google's sitemap guidelines. This ensures your Shopify sitemap aligns with the broader standards used by major search engines and reduces the risk of misinterpretation during indexing.
A sitemap is a structured map of a website’s pages that helps search engines discover and crawl content more efficiently. When Google Search Console reports that a sitemap could not be read, it signals a barrier to how Google discovers new or updated URLs under that property. This situation does not automatically mean your site is invisible to search engines, but it does raise the risk that newly published or reorganized pages may not be discovered promptly through the sitemap pathway. Understanding the nuance between a read failure and broader crawl issues is essential for diagnosing the root cause and restoring optimal indexing velocity.
In practice, you might see a message in Google Search Console such as "Sitemap could not be read." This could appear for a single sitemap file or multiple files, and it often correlates with technical problems that prevent Google from retrieving or parsing the file correctly. The immediate business impact is usually a slower or reduced visibility of newly added content through the sitemap, especially for sites that rely heavily on structured URL publication for priority indexing.
From an SEO perspective, the consequence depends on how robust your crawl signals are beyond the sitemap. If your site is otherwise easy to crawl (well-structured internal links, clean robots.txt, solid canonical practices) and Google discovers new pages via links, the impact may be limited. Conversely, for large catalogs of content added regularly via a sitemap, read failures can bottleneck indexing. It is prudent to treat a sitemap read failure as a signal to perform targeted troubleshooting rather than assuming a full indexing halt.
When a sitemap cannot be read, the Search Console interface typically surfaces several indicators that help you triage the issue. Pay attention to the following signals:
For authoritative guidance on the expected format and behavior of sitemaps, refer to Google's sitemap overview and the official Sitemap Protocol. These resources explain how Google parses sitemaps, common pitfalls, and recommended validation steps. Pairing these external references with in-house checks strengthens your debugging process and demonstrates best-practice adoption in your SEO playbook.
In addition to Google’s documentation, reviewing the sitemap protocol and validators (such as those provided by the Wikimedia or sitemaps.org ecosystems) can help you distinguish syntactic issues from host/configuration problems. The goal is to confirm that the sitemap is both accessible and well-formed before diving into deeper server or hosting configurations.
From a workflow perspective, treating the issue as a multi-layered problem accelerates resolution. Begin with quick accessibility checks, then validate the XML, verify host alignment, and finally inspect server responses and caching policies. This approach minimizes guesswork and creates a reproducible diagnostic path you can document for future maintenance.
Part 1 of this 12-part series establishes the conceptual framework for diagnosing a sitemap read failure. The subsequent parts will guide you through concrete, repeatable steps: verifying accessibility, validating syntax, ensuring host consistency, checking HTTP responses, identifying blocking rules, and implementing durable fixes. If you want to explore practical steps immediately, you can explore related checks in our broader services section or read practical guides in our blog.
Although this is an overview, you can start with a concise triage checklist that mirrors the logic of the deeper checks in later parts. First, copy the sitemap URL from Google Search Console and fetch it in a browser or a simple HTTP client to confirm it returns HTTP 200. If you receive a 403, 404, or 5xx, you know the problem lies beyond Google’s reach and within server or access controls. Second, ensure the sitemap is hosted on the same domain and protocol as the site property in Search Console. A host mismatch is a frequent cause of read failures. Third, validate that the sitemap is properly encoded in UTF-8 and adheres to the sitemap protocol (XML well-formed, proper closing tags, and correct URL entries).
Finally, remember that some environments employ security layers like firewalls, IP whitelists, or authentication barriers that can temporarily block automated retrieval of the sitemap. If you encounter persistent access issues, these components are among the first things to inspect. The next sections of this guide will walk you through each of these checks in a structured, repeatable way, so you can restore sitemap reliability with minimal downtime.
For continued reading, see Part 2, which dives into verifying basic accessibility and URL availability, including how to interpret HTTP status codes and content types. This progression ensures you have a solid, practical foundation before moving to more advanced validation and remediation steps.
As you advance through the series, you’ll develop a repeatable process you can apply to other properties and clients, reinforcing confidence that sitemap-related issues do not derail overall indexing momentum. The practical payoff is measurable: faster recovery times, more predictable indexing, and clearer communication with stakeholders about SEO health and resource allocation.
After confirming that a sitemap read failure is not a general crawl issue, the next critical step is to verify basic accessibility and URL availability. This phase focuses on whether Google can actually reach the sitemap file on your hosting environment, whether the domain and protocol match your Search Console property, and whether any simple access controls are inadvertently blocking retrieval. Getting these basics right often resolves read failures without complex remediation. For broader context, see Google's guidance on sitemap access and validation linked in the references at the end of this section.
When you start troubleshooting, keep the sitemap URL handy from Google Search Console. Your first moves are to confirm that the URL responds with HTTP 200 and serves XML content encoded in UTF-8. If the URL redirects, you should understand where the final destination sits and ensure that the end result remains a valid sitemap file rather than a misconfigured page or a generic HTML error.
Practically, you can perform these checks using common tools. A curl command such as curl -I https://example.com/sitemap.xml will reveal the HTTP status, content-type, and cache headers. If you see a 301 or 302 redirect, repeat the request using curl -L -I to follow the redirect chain and confirm the final status and content. A 200 status with an XML content-type is typically the fastest green signal that the URL is accessible and properly served.
In addition to direct fetches, validate the host alignment by inspecting the property settings in Google Search Console. If your property is configured for https://www.yourdomain.com, ensure the sitemap URL is not a lingering variation such as http://yourdomain.com/sitemap.xml or https://yourdomain.com/sitemap.xml. These misalignments are a frequent cause of "sitemap could not be read" messages even when the file itself is correct.
Another practical consideration is the sitemap’s hosting path. While sitemaps can live in subdirectories, Google prefers consistency between the sitemap location and the site’s canonical host. If your site uses multiple subdomains or a dynamic routing setup, document where each sitemap lives and ensure that the URLs listed inside the sitemap remain on the same host and protocol. A mismatch here can trigger host consistency checks within Search Console and prevent successful reads.
Finally, review any security appliances that might intermittently block automated access to the sitemap. Firewalls, WAFs (Web Application Firewalls), or CDN rules may temporarily block requests from Google’s IP ranges. If you suspect this, temporarily whitelisting Google’s crawlers for the sitemap path or adjusting rate limits can restore normal access while you implement longer-term controls.
Accessible sitemaps provide a reliable signal to Google about which URLs to prioritize for indexing. When a sitemap is read successfully, Google can more quickly detect new or updated content, particularly for large catalogs or sites with frequently changing pages. Conversely, persistent accessibility issues can slow down indexing velocity, increase time-to-index for new content, and complicate data-driven decisions about content strategy. However, it’s important to balance this with the overall crawlability of the site; strong internal linking and clean URL structures can help Google discover content even if the sitemap has occasional read issues. For deeper guidance on how sitemaps complement other crawl signals, consult the official sitemap overview from Google and the Sitemap Protocol documentation referenced below.
As you proceed, keep a running record of the checks you perform, the outcomes, and any changes you implement. This habit not only speeds up remediation for future issues but also strengthens your team’s transparency with stakeholders about SEO health. If you’d like to explore related routines, our services section and our blog contain practical guides on crawl optimization and ongoing site health.
For reference, Google’s official sitemap guidance emphasizes both accessibility and correctness of the file’s structure. See the sitemap overview and the Sitemap Protocol for details on how Google parses and validates entries. Connecting these external references with your internal diagnostic process reinforces best practices and improves audit quality across projects.
In the next section, Part 3, you will learn how to validate the XML sitemap syntax and encoding to ensure the file is structurally sound and machine-readable, which is a natural progression after establishing reliable access.
Until then, adopt a disciplined triage workflow: verify accessibility, confirm host consistency, inspect redirects, and review security controls. This approach minimizes guesswork, accelerates restoration of sitemap reliability, and supports smoother indexing momentum across property changes. For ongoing reference, you can also review our practical steps in the related sections of our services or revisit insights in the blog.
XML syntax and encoding govern whether Google can parse a sitemap file at all. If the file is not well formed or encoded correctly, Google may ignore it, which can slow down indexing for newly published pages. Verifying syntax and encoding is the most deterministic step you can take before investigating hosting, access controls, or network-related blocks. This part focuses on ensuring the sitemap is structurally valid and machine-readable, so Google can interpret the listed URLs without ambiguity.
Start with the basics of XML correctness and encoding. A correctly formed sitemap uses the sitemap protocol, starts with a proper root element, and keeps each URL entry encapsulated within a
http://www.sitemaps.org/schemas/sitemap/0.9 so Google can recognize the file as a sitemap.& rather than a raw &.When you encounter a read failure, this set of checks helps isolate whether the problem lies in XML structure, encoding, or a misconfigured entry. If you find a malformed tag or an unescaped character, correct the XML, save with UTF-8 encoding, and re-upload the file for testing in Google Search Console. For a deeper understanding of the protocol itself, you can review the Sitemap Protocol documentation and validate against the official schema.
Encoding determines how non‑ASCII characters are represented and understood by crawlers. The sitemap should be encoded in UTF‑8, and you should avoid introducing a BOM that can disrupt initial parsing. Pay attention to how special characters appear in URLs and metadata, ensuring they are properly escaped or percent-encoded as required by the URL syntax.
& for ampersands, < for less-than, and > for greater-than where applicable.Useful validation steps include running the sitemap through an XML validator and a sitemap-specific checker to confirm both well-formedness and protocol compliance. For a practical workflow, pair these checks with a quick token test in your browser or a curl request to confirm the file is served with a 200 status and the correct content type.
For hands-on validation, consider tools such as online XML validators and the official sitemap validators. They help you confirm that the file adheres to the XML syntax rules and the Sitemap Protocol schema, reducing back-and-forth between teams and speeding up restoration of indexing momentum. You can also reference authoritative resources in our blog for practical validation patterns and common pitfalls.
Employ a mix of automated checks and manual review to ensure accuracy. Start with a quick syntax check using an XML validator, then perform a protocol-level validation against the sitemap schema. If possible, run a local test instance of the sitemap to confirm that each
After you complete these checks, you should be ready to re-submit the sitemap in Google Search Console. Monitor the crawler signals for improved read status and indexing activity. If issues persist, Part 4 will guide you through verifying the sitemap location, host consistency, and the hosting environment to eliminate server-side blockers. For broader site health insights, explore our services page or consult related guidance in our blog.
Once accessibility checks pass, the next critical axis is ensuring the sitemap XML is structurally sound and protocol-compliant. Read failures often originate from malformed XML or misapplied namespaces. A well-formed sitemap doesn't guarantee indexing speed, but it removes avoidable friction that slows discovery of new URLs.
At the core of the problem is adherence to the Sitemap Protocol. The protocol defines precise rules for the root element, namespaces, and the required loc field for each URL. Deviation in any of these areas can trigger Google to treat the sitemap as unreadable or invalid. The most common culprits are missing
urlset with the proper sitemap namespace: xmlns="http://www.sitemaps.org/schemas/sitemap/0.9". loc tag with an absolute URL starting with http or https. lastmod, changefreq, and priority should follow their definitions and use correct data formats. Beyond the basic rules, consider the distinction between a standard sitemap and a sitemap index. A standard sitemap contains multiple
Validation is the quickest way to diagnose these issues. Use an XML validator or the sitemap-specific validator to check for well-formedness and protocol compliance. If your validator flags a namespace mismatch, check that the root element includes xmlns with the exact URL above. If a
For external references and deeper validation techniques, see Google's sitemap protocol guidance and third-party validators. The combination of validated syntax and correct protocol usage dramatically reduces the likelihood of read failures, and it supports more efficient indexing by Google. In addition to the official resources, many SEO teams benefit from the practical insights shared in reputable industry blogs and documentation on best practices for sitemap maintenance.
To align with best practices, consider hosting strategies that ensure fast, reliable access to the sitemap. If you’re using a content delivery network (CDN) or a load balancer, verify that the sitemap is not being cached in a way that serves stale content to Google. Use canonical host settings and consistent delivery paths to minimize scenario-based redirects that can complicate validation and indexing.
External resources you may find valuable include Google's sitemap overview and the official Sitemap Protocol. These resources explain how Google parses sitemaps, common pitfalls, and recommended validation steps. Pairing these external references with in-house checks strengthens your debugging process and demonstrates best-practice adoption in your SEO playbook:
From a workflow perspective, treat sitemap validation as a repeatable process you can apply across multiple properties. The ultimate objective is to maintain a trustworthy sitemap that Google can read reliably, which translates into more consistent indexing signals and faster visibility for newly published pages.
When you’re ready to apply these practices at scale, explore resources in our services or read more practical guides in our blog.
The error message "sitemap could not be read" is more than a technical nuisance; it signals a disconnect between your site and how search engines discover and interpret your structure. When Googlebot or other crawlers encounter a sitemap that they cannot read, they lose a reliable channel to understand which pages exist, when they were updated, and how they are related to one another. For sites like sitemapcouldnotberead.com, this can translate into slower indexing, incomplete coverage, and in some cases, missed opportunities to surface fresh content to users. Recognizing the implications early helps you minimize impact and maintain robust crawl efficiency.
In practical terms, the error creates a black box around your URL dossier. Google relies on sitemaps to cue its crawlers about new or updated content, priority signals, and the overall site taxonomy. When the sitemap is unreadable, the crawl can fall back to discovering URLs through internal links, external links, or direct discovery, which is often slower and less systematic. For SEO teams, that means less predictable crawl coverage, potential delays in indexing new content, and a higher likelihood of important pages remaining undiscovered for longer periods. This is especially consequential for e-commerce catalogs, news publishers, or any site with frequent content updates. To mitigate risk, many sites pair sitemaps with a robust internal linking strategy and ensure that key pages remain easy to find via navigation.
The message can arise from several root causes, all of which share a common theme: the sitemap file cannot be parsed or retrieved in its intended form. Typical triggers include syntax errors in the XML, incorrect encoding, oversized sitemap files, broken or misformatted URLs, access restrictions, and server-side issues that block crawlers. Some errors are temporary, tied to changes in hosting or DNS, while others are persistent until a specific fix is applied. Understanding the nuance of each trigger helps you determine whether a quick patch suffices or a deeper overhaul is required. For reference, Google’s documentation on sitemaps provides guidance on how to structure valid XML and what crawlers expect from a well-formed sitemap. See https://developers.google.com/search/docs/crawl-indexing/sitemaps/overview for details, and align your implementation with official standards.
To validate readability, you can use online XML validators and the crawl-diagnostic tools in Google Search Console. If your site employs a private hosting environment or a CDN, ensure that the sitemap is exposed publicly and that caching policies don’t serve stale or partial content.
For teams operating at scale, a single unreadable sitemap often traces back to a misalignment between file structure and the discovery expectations of crawlers. Large catalogs, rapid product updates, or frequent post revisions can push a sitemap beyond recommended size or update frequency. In such cases, proactive monitoring and modular sitemap design become essential. If you are already consulting our SEO services, you can discuss systemized approaches to sitemap architecture that scale with your site’s growth and update cadence.
Finally, it helps to remember that sitemap readability is not merely about the file itself. It’s also about how accessible the sitemap is to crawlers. Hosting providers, security configurations, and network restrictions can inadvertently shield the file from search engines. Ensure the sitemap URL is correct, public, and delivered with the proper content type, typically application/xml. If you want a quick sanity check, compare the sitemap URL in your robots.txt to confirm there are no disallow rules blocking access. You can review robots.txt best practices and how they interact with sitemaps in credible SEO resources, including guidance from authoritative sources.
By aligning sitemap readability with reliable delivery, you set a foundation for predictable crawl behavior. If you are unsure where to begin, you can explore our contact page for tailored assistance, or review the related sections on our services to understand how sitemap strategy integrates with broader SEO initiatives. For more technical context, consult official documentation and reputable SEO publications referenced above, and keep your internal processes aligned with current best practices in sitemap management.
Sitemaps are not just digital footprints; they are structured guides that help search engines understand your site’s architecture, surface new content quickly, and maintain accurate relationships between pages. For sitemapcouldnotberead.com, grasping the mechanics of how sitemaps work and how Google processes them lays the groundwork for diagnosing unreadable sitemaps more efficiently. This section outlines the core concepts, the typical sitemap formats, and the steps Google takes to read and interpret those files so you can align your implementation with practical, battle-tested practices.
At its essence, a sitemap is an XML document (or a set of them) that enumerates URLs on a site and optionally attaches metadata that signals freshness and importance. For Google and other crawlers, this reduces reliance on chance discovery through internal linking and external references. Instead, the sitemap becomes a deliberate directory that informs the crawler about what exists, what changed, and how pages relate to one another within the site taxonomy. When implemented well, sitemaps accelerate coverage for new or updated content and contribute to a more predictable crawl experience, which is beneficial for sites with dynamic catalogs or frequent publishing cycles.
There are several common sitemap formats, each serving distinct purposes. A standard XML sitemap captures regular pages and their metadata. Other formats include sitemap index files that point to multiple sitemap files, as well as image, video, and news sitemaps designed to cover media and special content types. The right mix depends on site structure, content strategy, and how aggressively you publish updates. For authoritative guidance, Google’s sitemap documentation provides a clear framework for structuring valid XML and leveraging specialized sitemap types when appropriate. See Google's sitemap guidelines for details on layout, encoding, and best practices.
Google begins by fetching the sitemap URL(s) you submit or declare in your robots.txt. Once retrieved, Google parses the XML to extract a sequence of <loc> entries representing actual URLs. Each <loc> is typically accompanied by optional metadata such as <lastmod>, <changefreq>, and <priority>—though Google emphasizes that these metadata signals are hints rather than hard rules. The primary signal Google uses is the URL itself and its accessibility, but the metadata can influence how soon or how often Google considers re-crawling a page. For more technical context, see the official guidance linked above and monitor behavior in Google Search Console’s Crawl reports.
After parsing the sitemap, Google queues eligible URLs for crawling. The crawl budget—the amount of resources Google allocates to a site—must be used efficiently, so maintaining a clean sitemap helps avoid wasted bandwidth on URLs that are duplicates, redirects, or already covered by other discovery signals. In practice, this means ensuring that the sitemap primarily lists canonical, indexable pages that you want crawled and indexed, rather than isolated assets or low-value pages. You can reinforce this by coupling sitemap entries with robust internal linking and a clear site architecture.
It is also important to understand the distinction between discovery and indexing. A sitemap can help Google discover new or updated pages faster, but indexing decisions depend on factors like content quality, page experience signals, canonicalization, and crawlability. When a sitemap is unreadable or inaccessible, Google reroutes its discovery strategy, which may slow indexing and reduce coverage of newly published content. That is why ensuring a readable, accessible sitemap is a foundational SEO practice.
To implement this effectively, you should verify that the sitemap is publicly accessible, served with the correct content type (typically application/xml or application/xml+gzip for compressed files), and updated to reflect the current structure of your site. If you rely on a CDN or caching layer, validate that the sitemap is not served stale content and that the latest version is visible to crawlers. For ongoing optimization, consider registering your sitemap with Google Search Console and periodically reviewing crawl diagnostics to catch anomalies early. When you need strategic help, our team can tailor sitemap-related improvements within broader SEO initiatives. Visit our services to learn more, or contact us for direct assistance.
In practice, the most effective sitemap strategies balance breadth and precision. A comprehensive sitemap that remains well-formed and updated, paired with a clean internal linking structure and a robust robots.txt configuration, creates a reliable pathway for crawlers to discover and index your content. This alignment reduces the risk of unreadable sitemaps causing gaps in indexing and helps maintain healthy crawl activity over time.
Unreadable sitemaps almost always trace back to a handful of practical issues. By cataloging the most frequent culprits, SEO teams can establish a repeatable diagnostic workflow that reduces downtime and preserves crawl coverage. This section focuses on the root causes, with concrete steps you can take to verify and remediate each one. For teams working on our services, these checks fit neatly into a broader sitemap optimization plan that complements ongoing technical SEO efforts for direct assistance.
Below, you’ll find the most frequent failure modes, organized for quick diagnosis. For each cause, start with a minimal validation pass, then escalate to targeted fixes that align with your site architecture and publishing cadence.
XML syntax problems are the most common trigger for a sitemap that cannot be read. Even a small syntax error—such as an unclosed tag, a misspelled element, or illegal characters in <loc> entries—can render the entire file invalid for parsing. Encoding mistakes, especially when non-ASCII characters appear in URLs or date stamps, can also break parsing rules for crawlers. In practice, these issues often originate from automated generation processes that do not strictly enforce XML well-formedness at scale.
What to check and how to fix:
<urlset> element with valid <url> entries.Tip: use Google’s official sitemap guidelines as a reference point for structure, encoding, and validation practices. Consider consolidating the validation workflow into a CI step so every sitemap rebuild is checked before deployment. If you need practical guidance tailored to your platform, our team can help map validation rules to your deployment pipeline.
For broader context on typical sitemap formats and how they’re interpreted by search engines, see external references such as Moz’s overview of sitemaps. Moz: What is a Sitemap.
Encoding mistakes often surface when URLs include non-ASCII characters or when lastmod timestamps use nonstandard formats. Also, missing schemes (http or https) or spaces in URLs can break parsing. Search engines expect precise, well-formed URLs and consistent timestamp formats. Even minor deviations can cascade into read failures.
Key remediation steps include:
If your sitemap lives behind a content delivery network or a security layer, verify that the encoding and content-type headers remain stable across cache refresh cycles. A mismatched header or stale cache can masquerade as a read failure even when the XML is technically valid. When you need a robust, repeatable encoding policy, our team can assist with implementation and validation aligned to your CMS or hosting environment.
Alongside practical checks, consider extending your sitemap approach with a sitemap index that references multiple smaller sitemaps. This reduces risk from large files and makes validation responsibilities more manageable. If you want to explore how to architect a scalable sitemap strategy, see our services or reach out via the contact page.
Large sitemaps are not inherently unreadable, but they become fragile when they approach platform limits or when they mix content types in ways that complicate parsing. Oversized files increase the surface area for errors and slow down validation cycles. Duplicates and inconsistent scope—listing the same URL under multiple entries or including non-indexable assets—dilute crawl efficiency and can cause confusion for crawlers trying to prioritize indexing.
Actions to mitigate these risks:
For large catalogs, this approach improves crawl efficiency and reduces the likelihood that readers encounter unreadable or partially loaded files. If you’re unsure how to segment your sitemap effectively, we can tailor a modular strategy that fits your site’s architecture and update cadence.
Access controls that block crawlers or misconfigure HTTP responses are frequent culprits in read failures. A sitemap that returns 403 or 401, or one that is behind a login or IP restriction, will not be readable by Googlebot or other crawlers. Similarly, intermittent 5xx server errors or timeouts prevent reliable retrieval, triggering crawl issues and stalled indexing.
Practical steps to address access problems include:
If you operate behind a firewall or OAuth-protected environment, consider offering a read-only public exposure for the sitemap to avoid crawl blocking. For ongoing assurance, configure automated health checks that alert you when the sitemap becomes temporarily unavailable or starts returning non-200 responses.
When you encounter a read failure caused by access or delivery issues, pair quick recoveries with a longer-term plan. Document the root cause, implement a targeted fix, and re-run validation to confirm successful read-by-crawlers before re-submitting to Google Search Console or other tooling. If you need a structured diagnostic workflow, our team can help design and implement it, ensuring that fixes are reproducible and tracked across deployments.
How to proceed next depends on your current setup. If you’re managing sitemaps manually, start with a thorough XML validation and a review of your hosting and caching layers. If you’re using an automated generator, integrate these checks into your CI/CD pipeline and consider splitting large files as a standard practice. For organizations seeking steady improvements, we offer tailored sitemap engineering as part of broader SEO optimization services. Explore our services or contact us for a targeted engagement that aligns with your publishing cadence and technical constraints.
This completes a focused look at the most common causes of sitemap read failures. In the next section, you’ll find guidance on interpreting error messages across tooling and how to translate those signals into concrete fixes that restore crawl coverage promptly.
When crawlers report read failures, the message is only the first clue. Interpreting the exact error signal within diagnostic tools is essential to map to concrete fixes. This part explains how to translate common messages into actionable steps that restore crawl coverage for sitemap could not be read issues.
Key tool surfaces include Google Search Console, the Sitemaps report, Crawl Stats, and live fetch diagnostics. Other platforms like Bing Webmaster Tools or your hosting provider dashboards can reveal complementary signals such as DNS problems or 5xx errors that block retrieval. Collecting these signals together helps you identify whether the root cause sits in the sitemap file, the hosting environment, or the delivery network.
To structure your triage, start with the most actionable observations: is the sitemap itself readable via a direct URL? Do you receive an HTTP 200 for the sitemap fetch? If the tool reports an XML parsing error, locate the line or entry with the culprit. If the tool reports a status like 403 or 401, focus on access permissions. If the messages indicate a DNS resolution failure, you know the issue is at the domain level rather than the file format.
For teams using Google Search Console, the Crawl and Sitemaps reports often provide a direct path from the error message to the affected sitemap URL and the exact line in the sitemap where the problem occurs. This direct mapping accelerates the fix cycle and reduces guesswork. If you need a guided assessment, you can review our services or contact us for a targeted diagnostic engagement tailored to sitemap reliability.
In addition to signal interpretation, maintain a running log of issues, fixes applied, and outcomes observed in subsequent crawls. This practice creates a feedback loop that improves both the tooling signals you rely on and the stability of your sitemap delivery. If you want hands-on help implementing a repeatable diagnostic protocol, explore our SEO services or reach out via the contact page.
Finally, as you integrate interpretive rigor into your workflow, align your conclusions with a broader sitemap maintenance plan. Clear ownership, defined SLOs for uptime of the sitemap URL, and automated checks reduce the risk of reintroducing unreadable sitemaps after deployment. For a scalable approach, consider our sitemap-focused services described on the /services/ page or contact us to schedule a tailored session.
A sitemap is a structured map of a website’s pages, designed to help search engines discover and understand content. For most sites, it serves as a navigational aid that communicates the breadth and depth of available URLs, their last modification dates, and how pages relate to one another. There are two common forms: an XML sitemap, which lists individual pages, and a sitemap index, which points to multiple sitemap files. When a site such as sitemapcouldnotberead.com relies on these files for crawl guidance, any disruption in access can slow or stall indexing. A failed read, often expressed as sitemap could not be read or couldn t fetch, signals more than a single server hiccup; it can indicate broader configuration or access issues that affect how search engines discover content. For stakeholders, recognizing the impact early helps preserve crawl efficiency and preserve existing rankings.
Guidance from authoritative sources emphasizes that sitemaps are especially valuable for large sites, sites with rapidly changing content, or sections that are hard to reach through internal linking alone. They are not a replacement for good internal linking, but they augment discovery when bots cannot easily find pages through the site’s navigation. For practitioners at sitemapcouldnotberead.com, this distinction translates into practical steps: ensure the sitemap is timely, complete, and reachable, while maintaining healthy crawlability across the entire domain.
From a strategic perspective, a functioning sitemap helps allocate crawl budget efficiently. When search engines encounter a readable sitemap, they gain explicit signals about updated content, priority, and frequency. If the sitemap cannot be read, the onus falls back to the site’s internal linking structure and external references for discovery. This is why early detection and remediation are critical for preserving indexing momentum, especially for new domains or sites with a large catalog of pages. For deeper reference on sitemap best practices, see Google's sitemap overview and guidelines from other major search engines.
In practice, the read fetch issue can appear in various forms: a sitemap that never loads, a file that returns errors, or a response that is blocked by server policies. Recognizing these symptoms is the first step toward a reliable remediation path. This part of the guide sets the stage for a systematic approach to diagnosing and fixing read fetch failures, so you can restore smooth crawling and indexing. To support ongoing maintenance, consider pairing sitemap monitoring with proactive checks of robots.txt, server access controls, and DNS health. This holistic view reduces the risk that a single fault blocks visibility for a large portion of the site.
If you are exploring related services or want a structured approach to SEO health, you may review our SEO Audit Service for a comprehensive crawl and indexability assessment. It complements the sitemap-focused guidance by validating internal linking, canonicalization, and site-wide accessibility across layers that influence how search engines crawl and index content.
In the sections that follow, we break down the read fetch scenario into actionable steps. You will learn how to verify URL accessibility, interpret HTTP responses, and distinguish between issues at the DNS, hosting, or network levels versus problems rooted in the sitemap file itself. The goal is to equip you with a repeatable diagnostic mindset that can be applied to any site facing a sitemap could not be read or couldn t fetch scenario.
Beyond technical fixes, sustaining sitemap health requires ongoing governance. Regularly validating the sitemap's structure, ensuring it remains within size limits, and keeping the sitemap index up to date with newly discovered URLs are essential practices. Building a monitoring routine that flags read fetch failures as soon as they appear helps maintain momentum in indexing and prevents gradual degradation of visibility. For authoritative guidance on sitemap integrity and schema, consult standard references in the field, and integrate insights into your internal playbooks.
When a sitemap cannot be read or fetched, several signals surface across diagnostic tools and server logs. Early recognition helps contain crawl disruption and preserve indexing momentum for a site like sitemapcouldnotberead.com. Identifying these symptoms quickly allows teams to distinguish between transient network blips and deeper configuration issues that block discovery of content.
One of the most immediate signs is a direct fetch error on the sitemap URL. If a search engine or a crawler attempts to retrieve sitemap.xml and receives a 404, 403, or a redirect to an error page, the sitemap cannot guide crawling and indexing for the pages it lists. This disrupts the explicit signals that help search engines prioritize updated content.
These symptoms warrant a targeted triage to distinguish between network, hosting, and content-level issues. In many cases, a quick check of the exact HTTP status, the agent used by the crawler, and the response headers clarifies where the fault lies. If the sitemap is served via a content delivery network (CDN) or gzip-compressed file, verify that the correct Content-Encoding header is applied and that crawlers can decompress the payload.
To guide remediation, rely on concrete steps rather than assumptions. A measurable signal is the combination of a failing fetch and a non-200 response from the sitemap URL, coupled with a corresponding log entry on the hosting stack. For more systematic guidance on sitemap health and indexability, you may review our SEO Audit Service for a comprehensive crawl and indexability assessment.
In practice, many read/fetch failures show up in batches rather than as isolated incidents. A temporally clustered set of errors often points to a recent deployment, a CDN edge node misconfiguration, or a temporary hosting outage. Maintaining a consistent diagnostic cadence helps ensure you don’t miss gradual degradation that affects crawl efficiency over weeks, not days.
A 404 status on the sitemap URL often signals that the file was moved, renamed, or was never deployed to the expected path. Confirm the exact location of the sitemap (for example, at the root or within a subdirectory) and verify that the web server hosts the file under that path. If you use a canonical domain or a preproduction environment, ensure the production URL is the one submitted to search engines.
403 responses typically indicate permission problems, such as restrictive .htaccess rules, an IP allowlist that doesn’t include search engine bots, or misconfigured sitemaps behind authentication. Review file permissions, directory traversal rules, and any security modules that might inadvertently shield the sitemap from legitimate crawlers.
Server-side failures can arise from temporary outages, resource limits during peak traffic, or misbehaving modules. Check server load, error logs, and any recent deployments that could destabilize the response path to the sitemap file. A brief maintenance window should be reflected in DNS and CDN health, with a plan to re-test once stability returns.
Malformed XML, incorrect encoding, or violations of the Sitemap XML schema prevent crawlers from parsing the file, even if it is served correctly. Validate the sitemap with an XML schema validator and confirm that special characters, CDATA blocks, and URL encoding comply with the standard sitemap protocol. If you use a sitemap index, ensure each referenced sitemap is valid and accessible.
Large sitemaps approaching the 50MB limit or more than 50,000 URL entries introduce the risk of partial loading or timeouts. When using a sitemap index, ensure all referenced sitemaps are reachable and properly linked. Review any automated sitemap generators to confirm they respect the size and URL constraints of the target search engines.
Because the sitemap serves as a discovery bridge, any reliability issue translates into reduced crawl velocity and potential skip of new or updated pages. The moment you observe any of the symptoms above, capture the exact URL, the status code, the date, and the user agent, then proceed with a controlled verification across multiple networks to determine if the problem is regional or global.
Ongoing monitoring is essential. A lightweight monitoring routine that checks the sitemap at regular intervals, complemented by robots.txt audits and DNS health checks, forms the baseline for sustainable sitemap health. If you want a structured, repeatable process, our team documents a diagnostic workflow in our SEO playbooks to help maintain a healthy crawl footprint across evolving site structures.
Regular health checks also support rapid detection of changes in hosting or network configurations. Coordinating with the hosting provider and CDN operator can reduce resolution time and minimize crawl disruption. For sites like sitemapcouldnotberead.com, a disciplined approach to symptoms translates into a resilient crawl strategy that sustains visibility even when technical hiccups occur.
Even when a sitemap file exists on the server, its usefulness depends on being accessible to crawlers. In most read/fetch failures, the root causes fall into three broad categories: server configuration, access controls, and the accuracy of the sitemap URL itself. Understanding how these areas interact helps prioritize fixes and prevents repeat incidents for a site like sitemapcouldnotberead.com.
To begin triage, map the problem to one of these three buckets. Each bucket has specific signals, easy verification steps, and common fixes that minimize downtime and preserve crawl momentum.
Recognizing where the fault lies informs the remediation plan. For example, a 404 on sitemap.xml that persists across multiple agents typically signals a path misalignment, whereas a 403 response often points to permission rules or IP blocks. If you need a guided, end-to-end diagnostic framework, our SEO Audit Service provides a structured crawl and indexability assessment designed to catch these core issues quickly.
The web server configuration determines how static files such as sitemap.xml are located and delivered. Common trouble spots include an incorrect document root, misconfigured virtual hosts, or rewrite rules that accidentally shield the sitemap from crawlers. Check for the following specifics: the sitemap is placed under the public document root, the file path matches what is published in robots or sitemap indexes, and that the server returns a 200 OK for requests from search engine user agents. For sites relying on CDNs, ensure the origin response is consistent and that edge rules do not strip the sitemap or serve a compressed payload with improper headers.
Review server logs around the time of fetch attempts to identify 4xx or 5xx errors, which indicate permission issues or temporary outages. Validate content-type delivery (ideally application/xml or text/xml) and confirm there are no unexpected redirects that would strip query strings or alter the URL used by the crawler. If you are unsure, perform a direct fetch using a tool like curl from different networks to confirm a consistent response across environments.
Access controls, including IP allowlists, firewalls, and web application firewalls (WAFs), can inadvertently block legitimate crawlers. When a sitemap fetch fails due to access rules, you may observe 403 errors, rate limiting, or bursts of blocked requests in logs. Practical checks include: verifying that search engine IPs and user-agents are permitted, inspecting any authentication requirements for the sitemap path, and reviewing security module logs for blocked requests linked to the sitemap URL.
Ensure that the sitemap is publicly accessible without authentication, unless you have a deliberate strategy to expose it via a controlled mechanism. If a WAF is in place, create an exception for sitemap.xml or for the sitemap path, and periodically review rules to avoid accidental blocks caused by criteria that are too broad. After changes, re-test by requesting the sitemap URL directly and via the crawler user-agent to confirm resolution.
The final category focuses on the URL itself. Linux-based hosting treats paths as case sensitive, so sitemap.xml at /sitemap.xml may differ from /Sitemap.xml. Likewise, the coexistence of http and https, www and non-www variants, and trailing slashes can create gaps between what is submitted to search engines and what actually exists on the server. Key checks include: ensuring the sitemap URL matches the exact path used by your server, confirming consistency across canonical domain settings, and validating that the sitemap index references valid, reachable sitemaps with correct relative paths.
Another frequent pitfall is misalignment between the sitemap’s declared URLs and the domain search engines crawl. If you publish a sitemap at https://example.com/sitemap.xml but robots.txt or the sitemap index references pages on http://example.org, crawlers will fail to map content correctly. Ensure the destination domain, protocol, and path are uniform across your sitemap, robots.txt, and submitted feed. For ongoing optimization, consider maintaining a simple mapping check as part of your weekly health routine, and consult our SEO Audit Service for rigorous checks on crawlability and indexability.
When a sitemap cannot be read or fetched, the first practical step is to verify the sitemap URL itself and the HTTP response it yields. This verification not only confirms the presence of the file but also uncovers whether the issue lies with the hosting environment, network path, or the sitemap content. For a site like sitemapcouldnotberead.com, a disciplined, manual verification process helps isolate transient glitches from systemic misconfigurations, enabling targeted remediation without unnecessary guesswork.
Begin with a direct check from multiple access points: a browser, a command line tool, and, if possible, a test from a different geographic region. This multidimensional check helps determine if the problem is regional or global and if it affects all crawlers equally or only specific user agents. The goal is to observe the exact HTTP status code, any redirects, and the final destination that a crawler would reach when requesting the sitemap.
For practical commands you can start with, use a browser-inspection tool or a curl-based approach. For example, a simple status check can be done by requesting the sitemap and observing the first line of the response headers. If curl is available, you can run: curl -I https://sitemapcouldnotberead.com/sitemap.xml. If a redirect is involved, follow it with curl -I -L https://sitemapcouldnotberead.com/sitemap.xml to see the final destination and the status at each hop. These actions clarify whether the problem is a 404, a 403, or a more nuanced redirect chain that fails to deliver the content to crawlers.
Beyond initial status codes, pay close attention to response headers. Key indicators include Content-Type, Content-Length, Cache-Control, and Content-Encoding. A mismatch in Content-Type (for example, text/html instead of application/xml) can cause crawlers to misinterpret the payload, even if the file is technically reachable. Content-Encoding reveals whether the sitemap is compressed (gzip, deflate) and whether the crawler can decompress it on the fly. If a sitemap is gzip-compressed, ensure the server advertises Content-Encoding: gzip and that the final, decompressed content remains valid XML.
One common pitfall is the subtle effect of redirects on crawlers. If a sitemap URL redirects to a page that requires authentication or to a page with a different canonical domain, search engines may abandon the fetch path. In such cases, conducting a redirect audit—documenting the exact chain and the HTTP status of each hop—helps determine whether the sitemap path is still a reliable entry point for crawl discovery.
In addition to direct checks, validate that the sitemap is accessible to common search engine bots by simulating their user agents in curl: curl -A 'Googlebot/2.1 (+http://www.google.com/bot.html)' -I https://sitemapcouldnotberead.com/sitemap.xml. Discrepancies between browser results and crawler simulations often signal access controls or firewall rules that treat bots differently than human users. If such discrepancies appear, review server access controls, IP allowlists, and security modules that could selectively block automated agents.
When access is restricted by a firewall or WAF, temporary whitelisting of the crawler IP ranges or user-agents can restore visibility while keeping security intact. After any change, re-run the same verification steps to confirm that the sitemap is consistently retrievable under both normal and crawler-like conditions. If you need a repeatable workflow to maintain this level of assurance, our SEO Audit Service provides a structured crawl and indexability assessment that incorporates sitemap reachability checks alongside broader site health indicators.
In cases where the sitemap is served through a content delivery network (CDN) or edge caching layer, replicate the checks at both the origin and the edge. A successful fetch from the origin but not from the edge indicates propagation delays, stale caches, or edge-specific rules that may require purging caches or updating edge configurations. Document the results across layers to pinpoint precisely where the barrier originates.
Finally, if the sitemap uses an index file to reference multiple sub-sitemaps, validate each referenced sitemap individually. A single inaccessible sub-sitemap breaks the integrity of the entire index and can prevent search engines from indexing a portion of the site even if other entries are healthy. The remediation path may involve regenerating the affected sub-sitemaps, correcting URL paths, or adjusting the index structure to reflect the actual site architecture.
As you complete this verification cycle, maintain a record of all observed results, including the exact URL, status codes, timestamps, and the agents used. This creates a traceable diagnostic trail that supports faster remediation and helps prevent recurrence. If you observe recurring patterns across multiple pages or domains, consider expanding the scope to include DNS health, hosting stability, and network-level routing—a holistic view that reinforces the reliability of your sitemap as a tool for efficient crawl and indexing.
For ongoing improvements and to ensure consistent visibility, you can complement this protocol with a formal sitemap health checklist and periodic audits. The goal is to preserve crawl efficiency and ensure timely indexing, even when infrastructure changes occur. If you want a rigorous, repeatable process for sitemap health, explore our SEO playbooks and services, including the SEO Audit Service mentioned above.
The message Shopify sitemap could not be read signals a disruption in how search engines discover and index a storefront’s pages. A sitemap is the map that helps crawlers understand the breadth and structure of your site. When that map is unreadable, search engines lose visibility into new products, collections, blog posts, and critical informational pages. For Shopify stores, where product feeds change frequently and timing matters for ranking and traffic, a readable sitemap is a core technical signal that supports rapid indexing and accurate representation in search results.
In practical terms, this error can slow or prevent the indexing of newly added products, price updates, and content revisions. The result is delayed visibility in search results, missed opportunities for organic traffic, and potential confusion for customers who rely on organic search to discover items that are in stock or on sale. From an ecommerce perspective, even a short window without readable sitemaps can translate into incremental drops in impressions and clicks, especially during product launches, promotions, or seasonal campaigns.
Shopify’s sitemap ecosystem is designed to be robust while remaining simple for store owners and developers. Shopify generates a core sitemap at the conventional location /sitemap.xml and many ecommerce sites rely on a hierarchy of sub-sitemaps that cover products, collections, blogs, and informational pages. When the sitemap cannot be read, that entire chain of signals is disrupted. The impact is not just about pages appearing in search; it also affects how search engines assess crawl frequency, canonical relationships, and freshness signals for category pages and blog entries.
For readers planning troubleshooting in stages, this article begins with the core concepts and then moves into practical diagnosis and fixes in subsequent parts. If you are evaluating the issue as part of a broader SEO audit, consider correlating sitemap readability with recent site changes, server performance, and how your Shopify theme interacts with URL generation and redirects. A readable sitemap complements other technical health checks, such as ensuring proper robots.txt directives and valid SSL, to maintain a healthy crawl budget and accurate indexing for a Shopify storefront.
Internal resources can help you navigate this concern. For a guided overview of how we approach Shopify sitemap audits and optimization, visit our Services page. External references from industry authorities provide additional context on sitemap best practices and validation practices, including Google’s guidance on sitemap structure and submission workflows. These sources reinforce the importance of readable sitemaps as a foundational SEO signal for ecommerce sites.
Understanding the baseline expectation is crucial. When the sitemap is readable, search engines can quickly parse the list of URLs, detect priority changes, and reprocess updates with minimal delay. When readability fails, the system behaves as if pages exist but are invisible to crawlers, which can lead to stale SERP listings and missed opportunities for visibility on high-intent queries.
From a strategic standpoint, this issue deserves prompt attention. It affects not only the technical health of the site but also the trust and reliability of the storefront in the eyes of both customers and search engines. A clear, accessible sitemap signals to all parties that the store is well-maintained, up-to-date, and capable of delivering a consistent user experience. That alignment is particularly important for Shopify merchants competing in crowded markets where crawl efficiency and rapid indexing can influence share of voice.
In the following sections, we progressively break down how sitemaps work conceptually, the typical structure for storefronts, common error signals to watch for, and practical steps to diagnose and repair issues. Each part builds on the previous one to create a practical, actionable roadmap you can apply to Shopify stores facing sitemap readability problems.
For a quick diagnostic reference, consider starting with a basic check of your sitemap URL in the browser or a curl request to confirm HTTP status. A healthy sitemap should respond with a 200 OK and deliver valid XML. If you see 4xx or 5xx errors, or a response that isn’t XML, you’re looking at the core symptoms of unreadability. The next steps will guide you through identifying the root cause and applying targeted fixes.
As you progress through this article, you’ll encounter concrete checks, validation steps, and recommended practices aligned with industry standards. The goal is to restore readable, crawlable sitemaps that enable Shopify stores to compete effectively in the organic search landscape.
Key external references you may consult include Google’s guidelines on building and submitting a sitemap and industry resources that detail validation practices for XML sitemaps. These sources provide authoritative context on protocol rules, encoding, and common pitfalls. By aligning with these standards, you reinforce the technical foundation that underpins strong SEO performance for Shopify stores.
When the sitemap is unreadable, the immediate consequence is a gap in how content is discovered and indexed. New products may not appear in search results promptly, which is particularly impactful during promotions or restocks. Category pages that rely on dynamic URL generation can also lag in representation if the sitemap cannot be parsed correctly. Even if the homepage and critical pages are accessible, the broader catalog sections may remain underindexed, reducing overall organic visibility and traffic potential.
From a user experience perspective, the timing of updates matters. If a price change, inventory adjustment, or new collection relies on sitemap-driven indexing, a delay in discovery translates into customer friction—items appearing as unavailable or out of stock in search results. That friction can push prospective buyers toward competitors, especially in fast-moving product categories. Addressing sitemap readability is thus not only a technical task but a business efficiency measure that supports revenue continuity.
In subsequent sections, you will find a practical diagnostic framework. It covers how to verify the sitemap is reachable, how to interpret common error signals, and how to implement fixes that align with Shopify’s hosting environment and sitemap generation patterns.
To keep this guidance grounded, it’s helpful to reference established best practices from industry authorities. Google’s sitemap documentation emphasizes the importance of well-formed XML and proper URL encoding, while SEO platforms highlight the role of sitemaps in signaling crawl priority and freshness. Integrating these principles with Shopify’s architecture yields a robust approach to maintaining readable and effective sitemaps over time.
This first part establishes the context and stakes of the issue. The upcoming sections will dive into the conceptual framework of sitemaps, typical storefront structures, common error signals, and step-by-step diagnostic procedures. The objective is to equip you with a reliable method to identify, verify, and repair unreadable sitemaps, so your Shopify store maintains strong visibility and crawl efficiency across search engines.
As you explore the subsequent parts, you’ll see practical checklists and concrete fixes that apply to common Shopify configurations, hosting nuances, and content strategies. While each part stands on its own, the full article provides a cohesive, evidence-based roadmap for sustaining sitemap readability and improving long-term SEO outcomes for Shopify stores.
Understanding what an unreadable sitemap signifies helps you prioritize technical fixes that unlock indexing and visibility. This part sets the foundation for a structured diagnostic series, where each subsequent segment translates the concept into concrete actions tailored to Shopify’s environment. By approaching the problem systematically, you can restore reliable crawl access and safeguard your storefront’s organic performance.
For further guidance on sitemap structure and submission workflows, refer to Google’s official documentation on sitemaps and to industry best practices that inform robust sitemap validation. These references reinforce a disciplined approach to maintaining sitemap readability as part of a comprehensive SEO program for Shopify stores.
A sitemap is a machine-readable map that tells search engines which pages exist and how often they change. The sitemap protocol defines a hierarchical approach: a root sitemap index lists child sitemaps, and each child contains the URLs of a particular content type. For Shopify stores, this architecture supports fast indexing as inventories fluctuate and new content is added.
Understanding the conceptual framework helps when diagnosing an unreadable sitemap. It clarifies what signals search engines rely on: URL patterns, last modification timestamps, and optional change frequency and priority. With this knowledge, you can identify whether the issue stems from a broken index, malformed XML, or access controls that block crawling.
At the heart of the protocol is the sitemap index at /sitemap.xml. This index is not a page to be shown to users but a machine-facing catalog that guides crawlers. Each entry in the index points to a child sitemap file, such as a product sitemap or a blog sitemap. The structure is designed to be scalable for stores with thousands of products and pages.
Inside each sitemap, the key data points include the URL, the last modification date, and optional change frequency and priority. For Shopify, these fields help search engines decide when to re-crawl a given URL and how much priority to assign to pages in the next crawl cycle. Aligning these fields with actual site activity supports more accurate indexing and fresher results.
In practice, the sitemap ecosystem is designed to scale with the catalog. The main sitemap.xml acts as an index, while sub-sitemaps categorize items by type: products, collections, pages, and blog posts. This distribution helps search engines maintain crawl efficiency as the catalog grows. If you manage the store with custom apps or external feeds, you’ll want to ensure those feeds are also included under the sitemap umbrella or clearly linked from the index.
For teams performing an SEO audit, a solid understanding of the structure informs where to look first when readability fails. A readable sitemap means crawlers can fetch the index, retrieve the child sitemaps, and then crawl the actual URLs without hitting dead ends. When the index is misconfigured or XML is malformed, crawlers may stop at the root or fail to parse the file entirely, leading to a broad drop in discovered content.
Within Shopify, you might also see the need to validate connectivity to the sitemap from your server or content delivery network. In some cases, misconfigured redirects or DNS resolution problems appear as unreadable sitemaps because crawlers cannot reach the index or the child sitemaps. Always verify that the sitemap URL returns a clean 200 status with valid XML content before delving into more complex issues. For a practical, services-driven approach to diagnosing and fixing sitemap problems, see our Services page for structured methodologies.
To reinforce best practices, consult authoritative references on sitemap design. Google's sitemap guidelines provide vital rules on encoding, URL normalization, and proper XML syntax. Aligning your Shopify sitemaps with these standards reduces the likelihood of parsing errors and helps ensure compatibility across search engines. You can review the official guidance here: Google’s sitemap guidelines.
The sitemap index acts as the control plane for discovery. Each entry in the index is a link to a child sitemap that focuses on a specific content type—products, collections, pages, or blog posts. This separation allows crawlers to prioritize updates in high-velocity segments (like new products or price changes) while still indexing evergreen content efficiently.
Shopify stores often see a predictable pattern: a product sitemap, a collection sitemap, a blog sitemap, and a pages sitemap. If a store adds a lot of content through apps or external feeds, those feeds should be covered by dedicated child sitemaps or properly linked from the index to avoid orphaned URLs. For more detail on how to align this structure with your store architecture, explore our Services page for templated sitemap configurations and integration guidance.
Understanding the content type boundaries helps in troubleshooting unreadable sitemaps. If a single child sitemap is inaccessible, it can appear as an unreadable overall sitemap even if the root index is healthy. Conversely, if the root index cannot load, the entire sitemap ecosystem becomes unusable for crawlers. The diagnostic approach should start with the index, then progressively test each child sitemap in isolation.
For ongoing health, keep the sitemap strategy aligned with general SEO best practices. This includes ensuring consistent canonicalization, avoiding duplicate URLs across sitemaps, and maintaining up-to-date lastmod values that reflect real changes. A robust sitemap system supports faster indexing and improves user-facing visibility for product launches and promotions.
Moving forward, the next section will translate these concepts into actionable diagnostics that you can run directly on a Shopify store. You’ll learn how to verify the root index, inspect representative child sitemaps, and validate a sample of URLs to pinpoint where readability breaks down. This practical mapping helps you avoid speculative fixes and focus on verifiable signals that improve crawlability and indexing speed.
The readability of your sitemap is a fundamental signal to search engines about crawlability and freshness. If the sitemap cannot be read, the feed of URLs that Shopify generates may not be discovered or indexed promptly. In practice, this undermines the accuracy and timeliness of product indexing, and increases the risk of missed opportunities during launches and promotions.
From a technical SEO perspective, readability is about parsable XML, valid encoding, and an accessible URL. When the sitemap is unreadable, tools like Google Search Console may report indexes or crawl issues that appear as gaps in coverage. The friction translates into longer indexing delays and potential misalignment with your internal update cadence.
Start with basic reachability checks. Confirm that visiting https://sitemapcouldnotberead.com/sitemap.xml returns a 200 status and serves XML content. If the response is a 404, 403, or any HTML instead of XML, you’ve located the core symptom. Next, validate the XML against the Sitemap protocol to catch stray characters, bad encoding, or structural mistakes such as unclosed tags.
Beyond the technical checks, consider the user experience and business signals. An unreadable sitemap doesn’t just stall indexing; it communicates a maintenance risk to search engines. Consistent crawl cycles inform Google of freshness for new products or price changes. If the sitemap remains unreadable for an extended period, it can contribute to slower recovery from seasonal updates or promotional spikes.
As you prepare to move to fixes in the next part, document the findings from these checks. Create a concise incident log noting the time of discovery, the exact error response, and any correlated changes on Shopify or the hosting environment. This record will help with audits, stakeholder communication, and future prevention strategies.
For reference, you can align with authoritative standards by reviewing Google’s sitemap guidelines and the XML sitemap protocol provided by sitemaps.org. These sources outline recommended structures, encoding rules, and submission workflows that inform how you structure and verify your sitemap for ecommerce stores.
Internal resources for a streamlined diagnostic approach include our dedicated Services page, which outlines the tools and processes we apply in sitemap audits. If you’re evaluating this issue as part of a broader SEO health check, link to our Services page to explore the audit framework we employ for Shopify storefronts.
As we continue, the next section will translate these diagnostic findings into concrete repair strategies tailored to Shopify. You’ll learn how to adjust theme configurations, app interactions, and server-level settings to restore a readable sitemap, reestablish crawl efficiency, and protect indexing signals during updates.
When a sitemap is unreadable, the signals that guide search engines to crawl and index your storefront become blurred. This part focuses on the most frequent error signals you will encounter in practice, translating technical symptoms into actionable insight. Recognizing these messages early helps you triage quickly and avoid extended periods of under-indexing, missed product launches, or stale content in search results.
In ecommerce SEO, timing matters. Readers delivering unreadable signals often reveal gaps in crawl coverage that can translate into slower indexing and reduced visibility for new or updated content. The goal of this section is to help you translate error banners, console messages, and server reports into concrete debugging steps that align with Shopify’s hosting and sitemap generation patterns.
These HTTP signals are the first breadcrumb trail. They inform you whether the problem is at the network edge, during content delivery, or within the application layer that generates the sitemap. When you see a mix of 4xx and 5xx responses, treat it as a sign to verify both the availability of the files and the health of the hosting environment before digging into URL-level issues.
Beyond the obvious HTTP sonars and XML syntax, keep an eye out for content-structure anomalies. For Shopify stores, this often appears as mismatches between the main sitemap index and its child sitemaps, or as child sitemaps that reference pages or collections that no longer exist. Such inconsistencies reduce crawl efficiency and can cause search engines to deprioritize the sitemap in favor of healthier signals from the rest of the site.
Search engines and validation tools will surface specific error messages. Google Search Console, Bing Webmaster Tools, and XML validators each expose telltale phrases like “XML parsing error at line X,” “missing required tag,” or “URL not allowed” that map directly to fixes described above. When you see these messages, align the suggested remediation with Shopify’s URL generation patterns, app-induced redirects, and potential theme-level URL rewrites.
Documenting these signals in an incident log improves traceability across audits and stakeholder communication. Note the exact sitemap URL, the error message, when the issue began, and any recent changes to apps, themes, or DNS settings. This record helps when coordinating with hosting providers or with our team through the Services page for a structured remediation plan.
As you interpret these signals, remember they are not isolated incidents. A single unreadable signal could cascade into broader indexing gaps across multiple content types. Prioritize fixes that restore the core sitemap’s health first, then validate downstream signals with real-world crawl attempts to confirm restoration of crawlability and indexing velocity.
With a clear map of common error signals in hand, you can plan a targeted sequence of checks: verify access to the root sitemap, test each child sitemap individually, validate the XML against the protocol, and confirm that URLs are correctly formed and reachable. This approach minimizes guesswork and aligns with Shopify’s hosting patterns and typical app interactions that may affect the sitemap.
If persistent unreadability remains after implementing fixes, it is prudent to escalate. Our Services page outlines a structured diagnostic framework for Shopify storefronts, including sitemap audits, root cause analysis, and remediation playbooks. External references from authoritative sources, such as Google’s sitemap guidelines, provide additional validation benchmarks to ensure your corrected sitemap remains compliant with industry standards: Google’s sitemap guidelines.
The practical takeaway is simple: treat error signals as a diagnostic language. When you can translate each message into a concrete action—such as validating a single child sitemap, correcting a malformed entry, or adjusting a redirect rule—you shorten the path from symptom to resolution. This disciplined approach helps Shopify stores maintain reliable crawl access, timely indexing, and strong organic visibility across search engines.
Encountering the message "search console sitemap could not be read" is a signal that Google faced an obstacle when attempting to access or parse your sitemap file. For website proprietors and SEO teams, that obstacle can translate into delayed indexing, incomplete coverage, and a mismatch between site changes and how they appear in search results. Understanding the fundamental meaning of this alert is the first step toward reliable remediation. In the context of the services we offer at sitemapcouldnotberead.com, clarity about the error helps you prioritize fixes and minimize disruption to your crawl budget and visibility.
The phrase "sitemap could not be read" indicates a breakdown between your sitemap file and the reader that Google uses to process it. This reader can fail for multiple reasons, including a server refusal, malformed XML, or access controls that prevent public retrieval. When Google cannot read the sitemap, it cannot reliably discover new URLs or detect updates to existing ones through that sitemap channel. Even if your site remains crawlable through standard linking, a non-readable sitemap reduces the efficiency of discovery, especially for large sites with frequent updates.
From a practical perspective, this error often correlates with one or more of these outcomes: delayed indexing of new pages, outdated entries staying in Google’s index, and a potential drop in structured data coverage tied to sitemap-driven discovery. The impact is not always dramatic, but for sites with large inventories or rapid content cycles, the gap can accumulate quickly. If you rely on the sitemap to communicate critical sections of your site, addressing readability becomes a high-priority move.
To frame the problem clearly, consider the sitemap as a navigational map for search engines. When the map is unreadable, Google’s crawlers must rely on other signals to find pages, such as internal links or external references. This shifts some of the indexing burden away from your sitemap and toward page-level discovery. In time, that can lead to slower updates in search results and a higher risk that newly published content remains unindexed or underindexed.
Indexing coverage is a core component of how a site appears in search. A readable sitemap accelerates discovery, helps prioritize indexing for important pages, and provides a structured signal about canonical pages, last modification dates, and update frequency. When the sitemap is unreadable, you lose a reliable feed that informs Google about new or updated content. The result can be a mismatch between what you publish and what Google knows about, which in turn affects organic traffic and the precision of crawling efforts.
Even if you maintain strong internal linking and robust technical SEO, the absence of a readable sitemap can slow down the initial discovery of pages that are not easily reachable by navigation alone. For larger sites, or sites with important pages that sit deeper in the structure, a functional sitemap remains a key asset for timely indexing. In the upcoming sections, we will translate this high-level importance into concrete checks you can perform to diagnose and fix the problem.
During diagnostics, it helps to remember that readability is a combination of accessibility and correctness. A sitemap can be publicly accessible but syntactically invalid, or it can be perfectly formed yet blocked by authentication layers. Both scenarios produce the same user-facing symptom in Search Console, albeit with different root causes. This distinction matters because it guides the set of remedies you apply first.
For readers who want structured guidance or hands-on help, our contact page connects you with specialists who can walk you through the assessment and remediation process. If you prefer self-service approaches, you can start by reviewing the sitemap file against standard best practices and then validating the structure with dedicated tools before resubmitting.
Finally, remember that this article series is designed to build a practical, step-by-step framework. In Part 2, we dive into verifying sitemap accessibility to confirm that the file is publicly reachable and returns a valid HTTP 200 when fetched directly. This builds the diagnostic foundation so you can move confidently into more technical checks without guessing at the root cause.
After establishing that a sitemap is unreadable in Search Console, the next critical step is to verify its accessibility from the public web. If Google cannot fetch the file directly, it cannot read its contents, even if the sitemap is correctly formatted. Ensuring that the sitemap URL is publicly accessible, without authentication or network-level blocks, forms the foundation of reliable remediation. At our services at sitemapcouldnotberead.com, we emphasize a systematic accessibility check as the first line of defense against continued indexing issues and degraded crawl efficiency.
Public accessibility means that Googlebot and other crawlers can retrieve the sitemap using a straightforward HTTP request without passing through login prompts, IP allowlists, or cookie-based gating. If a sitemap is only available behind a login wall or restricted by firewall rules, Google will treat it as unreadable, even if the file exists on disk. This separation between file presence and public reach is a common source of the error message we’re addressing in this guide. For large sites with frequent updates, a consistently readable sitemap accelerates indexing and helps ensure that critical pages are crawled in a timely manner, aligning with your content calendar and product launches.
To minimize guesswork, begin with a direct fetch test: can you retrieve the sitemap XML over HTTPS and receive a valid response, ideally HTTP 200? If the response shows a redirect, a different status code, or an authentication prompt, you have identified the chain or barrier you must dismantle before proceeding with further diagnostics.
The simplest, most reliable confirmation is an HTTP header check. A sitemap that returns 200 OK with a Content-Type of application/xml or text/xml is in the healthy zone for readability. If you encounter 301/302 redirects, verify that the final URL remains a sitemap and that the redirect chain does not point to a non-sitemap resource or a different domain that could trigger mixed content warnings in some crawlers. If you see 403 or 401 responses, authentication or permission barriers are in play and must be addressed before Google will read the sitemap.
Practical testing tools and methods can accelerate this process. In a browser, simply open the sitemap URL in an incognito window to confirm there is no active session requirement. In a terminal, commands like curl -I https://your-domain.com/sitemap.xml reveal the status line and headers, helping you spot unexpected redirects or authentication prompts quickly. If you do not control the hosting environment directly, coordinate with your hosting provider to confirm there are no IP-based blocks or firewall rules that would prevent public fetches.
As part of a robust diagnostic workflow, verify that a CDN layer (if used) is not caching an error page or blocking the crawler’s user agent. Sometimes, edge rules inadvertently serve a placeholder response to bots, which looks like a readable file but isn’t. In such cases, the direct fetch will fail or return non-XML content, which is a clear signal to adjust the CDN configuration or bypass it for the sitemap host path.
For further context on how Google and other search engines handle sitemaps, consult official documentation on sitemaps and submission workflows. See Google Search Central: Submit Sitemaps and Sitemaps Protocol. If you are unsure about the path to public accessibility or suspect a server-level misconfiguration, our contact page can connect you with a technical specialist for guided remediation.
When accessibility is confirmed, you are ready to proceed with structural checks to ensure the content of the sitemap itself is correct and aligned with best practices. Part 3 of this guide will explore server responses and headers in greater depth, including how to interpret non-200 responses and how to adjust server configurations to restore readability. For ongoing support, consider engaging our team to perform a structured sitemap health check and implement automated monitoring that alarms you when readability gaps reappear.
In summary, accessibility verification is the gatekeeper for the rest of the diagnostic process. Without a publicly readable sitemap, even a perfectly structured file cannot contribute to indexing or crawl efficiency. By following the steps outlined above, you establish a solid foundation for diagnosing deeper issues related to syntax, URL entries, and sitemap size, which we cover in Part 3 and beyond. If you’re ready to continue, proceed to the next section on server responses and header validation, and keep this accessibility checkpoint as your baseline reference.
Following the accessibility checks, the next diagnostic layer focuses on server responses and HTTP headers. These signals reveal whether the sitemap is served correctly to crawlers or blocked by edge configurations, misrouted redirects, or mistaken content types. Reliable readability starts with a clean response flow from server to client, ensuring Googlebot can fetch, parse, and ingest the sitemap data. For more context on best practices, see our services overview on sitemap health.
HTTP status codes alone do not guarantee readability. They must be paired with correct headers and stable final destinations. A 200 OK is ideal, but a 301/302 or 307 redirect can still deliver the sitemap if the final URL returns XML with a readable content type. Yet repeated redirects introduce crawl overhead and potential timeouts, especially for large sitemaps. A 403/401 response indicates access barriers, and a 4xx/5xx error means the sitemap is unreachable at the request path, requiring targeted fixes.
Beyond status codes, the headers themselves matter. Content-Type should be application/xml or text/xml, and charset should be UTF-8. Mislabeling as text/html can cause parsing errors, while incorrect encoding may corrupt URL decoding. Other headers like Content-Length help identify truncated files, and Cache-Control or Expires influence how often Google re-fetches the sitemap. When headers betray incongruities, Google’s crawlers may stop at the first readable checkpoint and still interpret the sitemap as unreadable.
If you verify that the server returns 200 OK and proper headers but the sitemap remains unread in Search Console, the issue likely lies in the content itself or in how the path is resolved by crawlers. In such cases, you should continue with the structural checks in Part 4, focusing on the XML syntax and sitemap protocol alignment. Our team can help perform a formal header-auditing service or guide you through a staged remediation plan. Reach out via the contact page for a consult, or explore our services for a structured sitemap health program.
As a practical habit, document any observed header anomalies and their fixes. A short-term workaround might involve bypassing a CDN for the sitemap path during remediation, while a longer-term solution centers on stable server configuration and automated monitoring. For ongoing support, consider an automated health check that alerts you when the sitemap becomes unreadable again, which can be integrated into your existing monitoring stack.
With server responses and headers aligned, you will have cleared a critical hurdle on the path to reliable indexing. The next section, Part 4, delves into validating the sitemap’s syntax and structure, ensuring each <loc> entry is well-formed and reachable. If you want a hands-on, guided assessment in the meantime, our team is ready to assist—book a time through the contact page or review how our sitemap health program operates. For authoritative guidance, see Google's official documentation on sitemaps: Submit Sitemaps and the Sitemaps Protocol.
With accessibility and server responses verified, the remaining frontier is the sitemap's internal correctness. This part focuses on XML syntax, encoding, and strict adherence to the sitemap protocol so Google can parse each
A sitemap must be a well-formed XML document. That means every opening tag has a corresponding closing tag, elements are properly nested, and there are no stray characters outside element boundaries. Each
Common syntax errors include missing closing tags, mismatched tag pairs, unescaped ampersands in URLs, and elements placed outside their parent containers. Such issues can render the entire sitemap unreadable by Search Console, even if most of the file is correct. Running the file through a modern XML validator helps surface these problems before you attempt a resubmission.
Use UTF-8 encoding and declare it at the top of the file with an XML declaration: <?xml version="1.0" encoding="UTF-8"?>. Inconsistent encoding or the presence of a Byte Order Mark (BOM) can trigger parsing issues in some environments. Ensure there are no hidden characters introduced during generation or transfer, as these can corrupt the XML structure and cause partial reads in Search Console.
Standard page sitemaps use a
Ensure there are no URLs using unsupported schemes, empty
After validating structure, run a validator to confirm schema compatibility. This practice catches issues that manual reviews might miss and provides a concrete remediation path before you resubmit to Google Search Console.
Guided remediation remains essential when you manage large or complex inventories. If you want hands-on help, our sitemap health program offers structured syntax checks and ongoing monitoring. Reach out via the contact page, or explore our services for a comprehensive remediation plan. For authoritative guidance, refer to Google Search Central: Submit Sitemaps and Sitemaps Protocol.
In the next section, Part 5, we turn to verifying the actual URL entries within the sitemap to ensure each
When Google reports that a sitemap could not be read, site owners often worry about indexing and crawl health. This error typically arises when Google attempts to fetch the sitemap URL (for example, https://yourdomain.com/sitemap.xml) and receives an unexpected response or encounters a malformed document. Understanding the underlying causes is essential for maintaining a healthy crawl budget and ensuring that new or updated pages are discovered in a timely manner.
A sitemap is a map for search engines. It helps crawlers prioritize pages, especially in large sites or sites with rich media, dynamic content, or pages gated behind filters. However, when the sitemap itself cannot be read, the benefits are lost. Google may still find URLs through internal links or external references, but the absence of a readable sitemap reduces visibility for newly added or updated pages and can slow down indexing. The net effect is a longer time to appear in search results and, in some cases, incomplete coverage of your latest content.
From an SEO perspective, the error matters for crawl efficiency and indexing health. If Google cannot access your sitemap, it loses a reliable signal about which pages exist and how often they should be crawled. This can result in pages being crawled less frequently, or new pages remaining unindexed for longer than desired. For large sites or sites with frequent updates, a readable sitemap becomes even more critical to ensure timely indexing of changes.
To frame expectations: a readable sitemap does not guarantee immediate indexing, but a readable sitemap increases the likelihood that Google will discover and prioritize critical pages. Conversely, a consistently unreadable sitemap can create gaps in coverage, especially for pages that are not well linked internally. Guidance from authoritative sources emphasizes the value of a well-formed sitemap and clear delivery to the crawler. See the official sitemap guidance from Google for best practices: Google Search Central: Sitemaps and the standard sitemap protocol at Sitemaps.org Protocol.
This part of the article lays the groundwork for a practical diagnostic journey. Part 2 will walk you through verifying the error and gathering evidence to pinpoint root causes. You’ll learn how to reproduce the problem, capture error messages, and assemble logs or screenshots that help separate transient issues from persistent configuration problems. Until then, note that the goal is to move from merely observing an error to understanding its origin and the corrective steps that follow.
The discussion also highlights how Google treats sitemap submissions in the Search Console. When a sitemap cannot be read, the Console typically reports the cause alongside the URL. This contextual data is invaluable for prioritizing fixes, especially when multiple sitemaps or sections of a site are involved. As you prepare to diagnose, consider a minimal, testable sitemap to isolate issues without affecting the broader sitemap index.
urlset root element.For teams seeking a structured repair path, the rest of the article series offers a step-by-step framework. Part 1 introduces the error, its impact, and the mindset for a reliable remediation process. In Part 3, you’ll verify the sitemap URL accessibility, ensuring that HTTP status codes, permissions, and delivery headers permit successful retrieval from the site domain. This approach aligns with industry best practices for maintaining crawl efficiency and robust indexing.
If you want introductory guidance on diagnosing and repairing sitemap issues, our services page outlines practical command-center workflows for technical SEO health. You can also explore our knowledge base for common troubleshooting steps and examples of well-formed sitemaps. For ongoing optimization, consider setting up automated validation routines that alert you when a sitemap becomes unreadable again, reducing downtime and preserving crawl momentum.
In summary, a sitemap that cannot be read by Google translates to potential gaps in index coverage and slower visibility of updates. Recognizing this early and following a structured diagnostic path helps protect your site’s search performance and ensures your content is reliably discovered and prioritized by crawlers.
As you begin the diagnostic journey, keep the key objective in focus: restore readable, valid, and up-to-date sitemaps that accurately reflect your site’s structure and content. The next parts of this guide will provide concrete steps to verify the error, validate the XML, and address common causes with actionable remediation techniques. In the meantime, the essential takeaway is that a readable sitemap is a foundational asset for efficient crawling and timely indexing.
For quick reference, it helps to bookmark authoritative resources and align your remediation plan with established guidelines. Google’s documentation emphasizes proper sitemap formatting, correct HTTP delivery, and regular validation to prevent such errors from recurring. Begin with the fundamentals: confirm accessibility, validate XML, and verify that the sitemap contents accurately enumerate your live URLs. With these steps, you establish a solid baseline for future maintenance and scalable SEO health.
Accurate troubleshooting starts with reproducibility. In this phase you validate that the sitemap unreadable issue is consistent, captures the same symptoms across environments, and yields concrete signals that point to a root cause. Collecting organized evidence reduces guesswork and accelerates a targeted remediation plan.
Begin by reproducing the problem outside of critical production paths. Request the sitemap URL directly in a browser to observe status codes and response content. Note whether the response is a well-formed XML, an HTML error page, or a binary payload. If the URL requires authentication or IP access, document those constraints as potential blockers. This initial test helps distinguish server-side delivery issues from content-level problems inside the XML.
Next, verify the delivery at the HTTP layer. Use a simple head or get request to fetch the sitemap headers and status code. Tools like curl or HTTP client libraries reveal important details such as Cache-Control, Content-Type, Content-Encoding, and the exact status code. Pay attention to frequent culprits: 403 forbidden, 404 not found, 500 internal server error, and 301/302 redirects that may not preserve the expected content type.
Cross-check access restrictions by querying the sitemap index (if present) and the robots.txt file. Ensure the sitemap path is not inadvertently blocked by robots.txt rules or security policies that gate the XML feed. A classic signal of blockages is a legitimate URL returning a 200 for the page but a 403 or 404 for the sitemap resource. Document any such discrepancies with exact URLs and timestamps.
Consult Google Search Console (GSC) and the Sitemap reports for precise error messages. GSC often surfaces the specific cause alongside the sitemap URL, such as parsing errors, invalid XML, or unreachable resources. Exporting these messages alongside server logs creates a robust evidentiary trail that guides subsequent fixes.
With a consolidated evidence set, you can begin narrowing down root causes. Typical signals include misconfigured XML, restricted access, and inconsistent delivery headers. If you discover a transient outage or a temporary hosting glitch, document the window and monitor whether the issue recurs. For persistent problems, prepare a minimal, reproducible sitemap test and compare its behavior to your production feed.
For teams seeking structured guidance, our SEO services page offers workflows that standardize diagnostic playbooks and remediation steps. You can review practical frameworks and automation options at our SEO services. For reference, consult authoritative guidance on sitemap validation from Google and the standard sitemap protocol to align your approach with best practices: Google Search Central: Sitemaps and Sitemaps Protocol.
As you finalize the verification step, maintain a clear mapping between observed signals and potential causes. This alignment will inform the next stage: validating the XML syntax, ensuring proper indexing signals, and isolating whether the issue lies with delivery, content, or configuration. The next section delves into checking the sitemap URL accessibility with rigorous tests that isolate network, permission, and server-layer issues.
If you want a quick starting point, begin with a public, minimal sitemap example that lists a handful of representative URLs. Compare its behavior to your full sitemap to identify whether the problem is systemic or isolated to specific entries. This approach helps you rapidly confirm whether the root cause is structural (XML or delivery) or content-specific (invalid URLs or blocked resources).
Accessibility testing for a sitemap starts with the simplest question: can Google reach the sitemap.xml file from the public internet without hitting blocks or misrouting? In this phase you verify that the sitemap URL is reachable, delivered in the correct format, and not impeded by network protections, access controls, or misconfigurations. The goal is to isolate delivery issues separate from content or syntax problems so you can move quickly to the right remediation steps.
Begin by testing the URL from a browser on a representative external network. If the page loads and you see XML markup, that’s a strong signal. If you encounter a red error screen or a permission block, you’ve pinpointed a delivery barrier worth addressing before you dig into XML syntax. This early signal helps you avoid chasing XML fixes when the root cause is network-level or access-related.
To quantify accessibility, use command-line requests alongside browser tests. This ensures you observe both user-agent behavior and server-side delivery. A typical workflow includes inspecting HTTP status codes, response headers, and any redirects that could alter the payload. Remember: Google can handle gzip-compressed sitemaps, but you still need to ensure the content type and encoding are recognized by crawlers.
Execute a simple head request to check the status and headers without downloading the full file:
curl -I https://yourdomain.com/sitemap.xmlIf the response is 200 OK with a Content-Type of application/xml or text/xml, you’re typically in the clear for delivery. If you encounter a 301/302, follow the redirect to confirm the final destination serves a valid sitemap and preserves the correct content type. If a 403 or 404 appears, investigate access controls, path accuracy, and the existence of the file at the exact URL. For longer inspections, enable redirects:
curl -I -L https://yourdomain.com/sitemap.xmlConsider also checking for content encoding. A header like Content-Encoding: gzip means the payload is compressed; Google can fetch compressed sitemaps, but you should verify that the compressed stream decompresses correctly when you inspect it offline. If you see Content-Type mismatches or missing payload, the issue likely lies with server configuration rather than the sitemap content itself.
Next, confirm there are no blocks from robots.txt or security rules that inadvertently disallow access to the sitemap path. Fetch the robots.txt directly and search for any rules that might apply to /sitemap.xml. A common pitfall is a broad Disallow rule that unintentionally blocks the sitemap feed or related index files. If robots.txt appears to grant access but the server still returns a block, review security layers like WAFs, CDN protections, and IP allowlists.
If your site uses a sitemap index, verify that each referenced sitemap URL is accessible in the same manner. A failure in any child sitemap will manifest as issues in Google’s Sitemaps report, even if the index itself returns 200. Use the same curl tests against each listed sitemap URL and note any discrepancies in status codes or content types.
Network and hosting environments can also influence accessibility. For example, CDNs or edge servers may require a valid TLS certificate, stable DNS resolution, and correct SNI handling. Test from multiple networks or a staging environment to identify if the issue is isolated to a specific network path. If you detect TLS problems (expired certificate, chain issues, or mismatched domain names), correct them promptly to restore trust and crawlability.
When accessibility is established, you can proceed to validate the XML syntax and structure with confidence. If you want a guided remediation framework aligned with proven practices, explore our SEO services for structured diagnostic playbooks and automation options that help prevent accessibility regressions. For reference on best practices, you can consult foundational guidance from the XML and sitemap communities, and keep your remediation aligned with recognized standards and industry norms.
In summary, ensuring the sitemap URL is accessible is a foundational step in restoring readable, crawl-friendly signals for Google. By confirming public reachability, validating response codes and headers, and removing access roadblocks, you lay a solid groundwork for the next phase: validating the XML itself and confirming every listed URL is crawl-ready. This approach reduces guesswork, shortens remediation cycles, and enhances overall indexing health as part of a disciplined technical SEO workflow.
Even after you verified the issue, many unreadable sitemap problems come from deeper configuration faults. This section breaks down the most common root causes and gives you a practical method to isolate the offender without guessing. A precise diagnosis accelerates remediation and protects crawl momentum for your site on sitemapcouldnotberead.com.
The first set of culprits centers on the sitemap’s XML itself. If the XML is malformed or misdeclared, Google cannot parse URLs in a meaningful way, even if the file is reachable. Start with a quick validation pass against the sitemap protocol and ensure the root element <urlset> exists with the correct namespace declaration.
&.When these issues exist, the sitemap may still load in a browser but fail validation by Google’s crawler. To confirm, use an XML validator and compare against the official protocol guidance. See Google’s authoritative guidance on sitemaps for best practices and common pitfalls: Google Search Central: Sitemaps and the standard Sitemaps.org Protocol.
Delivery and encoding issues form the second major cluster. Even a well-formed XML can be unreadable if the response headers misrepresent the payload. Confirm that the sitemap is served with the correct Content-Type (application/xml or text/xml) and that any compression via Content-Encoding is properly handled by the client and Googlebot. A gzip-encoded sitemap must include the appropriate header and should be decompressed successfully by Google.
Size and segmentation concerns account for a third common category. Large sitemaps or sprawling sitemap indexes can overwhelm both servers and search engines if not structured properly. Google imposes practical limits on per-sitemap size and URL count. Splitting into multiple files and using a sitemap index not only improves reliability but also enhances crawl efficiency for large sites.
Access controls and network restrictions represent a fourth critical factor. If the sitemap URL sits behind basic authentication, IP allowlists, or a WAF rule, Googlebot will be blocked during fetch attempts. Ensure the sitemap is publicly accessible, not hidden behind login walls, and permitted by robots.txt. A quick public-access test, or a curl request from a representative environment, helps rule out authentication or IP-based blocks.
Beyond these core categories, a few other technical nuances can delay readability. CDN caching may serve stale versions of the sitemap, or dynamic sitemap generation could produce intermittent results during deployments. If you deploy frequent changes, consider versioning your sitemap URLs or invalidating CDN caches promptly after updates. Regularly validating the live sitemap after deployments minimizes the risk of fresh unreadable content.
A practical diagnostic approach is to map each root cause to a concrete test: verify XML structure with validators, fetch HTTP headers and status codes, confirm public accessibility, and segment large files where needed. This methodical flow reduces guesswork and aligns remediation with verifiable signals. If you need a structured workflow, our SEO services provide technical-audit templates and remediation playbooks that mirror this diagnostic rigor, and our knowledge base hosts field-tested examples of well-formed sitemap configurations.
As you work through root causes, remember that re-submitting the corrected sitemap to Google Search Console is a key milestone. The Sitemaps report will reveal whether Google accepts the file and will flag any remaining issues in a timely way. For authoritative guidance on ongoing validation, consult Google’s sitemap guidance and the Sitemaps Protocol documentation.
If you prefer external expert support, our team can help design robust validation routines that alert you to unreadable sitemaps before they impact indexing. You can also reach out via our contact page for a quick diagnostics session. A proactive approach to sitemap health reduces downtime and sustains reliable discovery for your site’s pages.
A sitemap is a compact map of a website's architecture, crafted to help search engines discover, understand, and prioritize content. When a read fetch failure occurs, such as a sitemap could not be read or couldn’t fetch, the impact goes beyond a single missing file. It can slow crawling, delay indexing, and reduce visibility for new or updated pages. For a site like sitemapcouldnotberead.com, early recognition matters because crawl budgets are finite and search engines allocate resources based on signals provided by the sitemap as well as by internal linking. In practical terms, a readable sitemap helps engines understand which pages to crawl most aggressively and how often those pages change. When the sitemap is unreadable, crawlers revert to relying on internal links and surface cues, which may lead to uneven indexing momentum across sections of the site.
From a governance perspective, sitemaps are particularly valuable for large catalogs, rapidly updated sections, or areas that are hard to reach through site navigation alone. They are not a replacement for solid internal linking; rather, they augment discovery when bot access to certain pages is constrained. For SEO Audit Service clients, this distinction translates into concrete remediation steps: keep the sitemap timely, complete, and accessible, while ensuring the broader crawlability of the site remains healthy across domains and hosting environments.
In practice, read fetch failures surface in several forms: a sitemap that never loads, a file that returns HTTP errors, or a response blocked by server policies. Recognizing these symptoms early allows teams to separate transient network hiccups from deeper configuration or access issues that block discovery of content. This initial section sets the stage for a systematic approach to diagnosing and repairing read fetch failures, so crawl activity can proceed with minimal interruption.
Beyond the technicalities, sustaining sitemap health requires ongoing governance. Regularly validating the sitemap's structure, ensuring it respects size limits, and keeping the sitemap index up to date with newly discovered URLs are best practices that prevent drift. A monitoring routine that flags read fetch failures as soon as they appear helps maintain indexing momentum, particularly for new domains or sites with extensive catalogs.
As you follow this guide, you’ll learn how to verify URL accessibility, interpret HTTP responses, and distinguish issues originating in DNS, hosting, or network layers from problems rooted in the sitemap file itself. The goal is to develop a repeatable diagnostic mindset that can be applied to any site facing a sitemap could not be read or couldn’t fetch scenario. For teams seeking a structured, enterprise-grade workflow, our SEO playbooks incorporate sitemap health with broader crawlability and indexability checks to sustain visibility across evolving site structures.
For organizations managing multiple sites or domains, the takeaway is clear: treat the sitemap as a living contract with search engines. Keep it fresh, validated, and aligned with robots.txt directives, canonical settings, and the actual pages on the server. This alignment minimizes the risk that a single unreadable sitemap blocks indexing momentum for large swaths of content. If you want a repeatable, evidence-based framework for maintaining sitemap health, explore our SEO Audit Service to formalize the checks described above and to integrate them into your ongoing SEO governance.
When a sitemap cannot be read or fetched, several signals surface across diagnostic tools and server logs. Early recognition helps contain crawl disruption and preserve indexing momentum for a site like sitemapcouldnotberead.com. Identifying these symptoms quickly allows teams to distinguish between transient network blips and deeper configuration issues that block discovery of content.
One of the most immediate signs is a direct fetch error on the sitemap URL. If a search engine or a crawler attempts to retrieve sitemap.xml and receives a 404, 403, or a redirect to an error page, the sitemap cannot guide crawling and indexing for the pages it lists. This disrupts the explicit signals that help search engines prioritize updated content.
These symptoms warrant a targeted triage to distinguish between network, hosting, and content-level issues. In many cases, a quick check of the exact HTTP status, the agent used by the crawler, and the response headers clarifies where the fault lies. If the sitemap is served via a content delivery network (CDN) or gzip-compressed file, verify that the correct Content-Encoding header is applied and that crawlers can decompress the payload.
To guide remediation, rely on concrete steps rather than assumptions. A measurable signal is the combination of a failing fetch and a non-200 response from the sitemap URL, coupled with a corresponding log entry on the hosting stack. For more systematic guidance on sitemap health and indexability, you may review our SEO Audit Service for a comprehensive crawl and indexability assessment.
In practice, many read/fetch failures show up in batches rather than as isolated incidents. A temporally clustered set of errors often points to a recent deployment, a CDN edge node misconfiguration, or a temporary hosting outage. Maintaining a consistent diagnostic cadence helps ensure you don’t miss gradual degradation that affects crawl efficiency over weeks, not days.
A 404 status on the sitemap URL often signals that the file was moved, renamed, or was never deployed to the expected path. Confirm the exact location of the sitemap (for example, at the root or within a subdirectory) and verify that the web server hosts the file under that path. If you use a canonical domain or a preproduction environment, ensure the production URL is the one submitted to search engines.
403 responses typically indicate permission problems, such as restrictive .htaccess rules, an IP allowlist that doesn’t include search engine bots, or misconfigured sitemaps behind authentication. Review file permissions, directory traversal rules, and any security modules that might inadvertently shield the sitemap from legitimate crawlers.
Server-side failures can arise from temporary outages, resource limits during peak traffic, or misbehaving modules. Check server load, error logs, and any recent deployments that could destabilize the response path to the sitemap file. A brief maintenance window should be reflected in DNS and CDN health, with a plan to re-test once stability returns.
Malformed XML, incorrect encoding, or violations of the Sitemap XML schema prevent crawlers from parsing the file, even if it is served correctly. Validate the sitemap with an XML schema validator and confirm that special characters, CDATA blocks, and URL encoding comply with the standard sitemap protocol. If you use a sitemap index, ensure each referenced sitemap is valid and accessible.
Large sitemaps approaching the 50MB limit or more than 50,000 URL entries introduce the risk of partial loading or timeouts. When using a sitemap index, ensure all referenced sub-sitemaps are reachable and properly linked. Review any automated sitemap generators to confirm they respect the size and URL constraints of the target search engines.
Because the sitemap serves as a discovery bridge, any reliability issue translates into reduced crawl velocity and potential skip of new or updated pages. The moment you observe any of the symptoms above, capture the exact URL, the status code, the date, and the user agent, then proceed with a controlled verification across multiple networks to determine if the problem is regional or global.
Ongoing monitoring is essential. A lightweight monitoring routine that checks the sitemap at regular intervals, complemented by robots.txt audits and DNS health checks, forms the baseline for sustainable sitemap health. If you want a structured, repeatable process, our team documents a diagnostic workflow in our SEO playbooks to help maintain a healthy crawl footprint across evolving site structures.
Regular health checks also support rapid detection of changes in hosting or network configurations. Coordinating with the hosting provider and CDN operator can reduce resolution time and minimize crawl disruption. For sites like sitemapcouldnotberead.com, a disciplined approach to symptoms translates into a resilient crawl strategy that sustains visibility even when technical hiccups occur.
Even when a sitemap file exists on the server, its usefulness depends on being accessible to crawlers. In most read/fetch failures, the root causes fall into three broad categories: server configuration, access controls, and the accuracy of the sitemap URL itself. Understanding how these areas interact helps prioritize fixes and prevents repeat incidents for a site like sitemapcouldnotberead.com.
To begin triage, map the problem to one of these three buckets. Each bucket has specific signals, easy verification steps, and common fixes that minimize downtime and preserve crawl momentum.
Recognizing where the fault lies informs the remediation plan. For example, a 404 on sitemap.xml that persists across multiple agents typically signals a path misalignment, whereas a 403 response often points to permission rules or IP blocks. If you need a guided, end-to-end diagnostic framework, our SEO Audit Service provides a structured crawl and indexability assessment designed to catch these core issues quickly.
The web server configuration determines how static files such as sitemap.xml are located and delivered. Common trouble spots include an incorrect document root, misconfigured virtual hosts, or rewrite rules that accidentally shield the sitemap from crawlers. Check for the following specifics: the sitemap is placed under the public document root, the file path matches what is published in robots or sitemap indexes, and that the server returns a 200 OK for requests from search engine user agents. For sites relying on CDNs, ensure the origin response is consistent and that edge rules do not strip the sitemap or serve a compressed payload with improper headers.
Review server logs around the time of fetch attempts to identify 4xx or 5xx errors, which indicate permission issues or temporary outages. Validate content-type delivery (ideally application/xml or text/xml) and confirm there are no unexpected redirects that would strip query strings or alter the URL used by the crawler. If you are unsure, perform a direct fetch using a tool like curl from different networks to confirm a consistent response across environments.
Access controls, including IP allowlists, firewalls, and web application firewalls (WAFs), can inadvertently block legitimate crawlers. When a sitemap fetch fails due to access rules, you may observe 403 errors, rate limiting, or bursts of blocked requests in logs. Practical checks include: verifying that search engine IPs and user-agents are permitted, inspecting any authentication requirements for the sitemap path, and reviewing security module logs for blocked requests linked to the sitemap URL.
Ensure that the sitemap is publicly accessible without authentication, unless you have a deliberate strategy to expose it via a controlled mechanism. If a WAF is in place, create an exception for sitemap.xml or for the sitemap path, and periodically review rules to avoid accidental blocks caused by criteria that are too broad. After changes, re-test by requesting the sitemap URL directly and via the crawler user-agent to confirm resolution.
The final category focuses on the URL itself. Linux-based hosting treats paths as case sensitive, so sitemap.xml at /sitemap.xml may differ from /Sitemap.xml. Likewise, the coexistence of http and https, www and non-www variants, and trailing slashes can create gaps between what is submitted to search engines and what actually exists on the server. Key checks include: ensuring the sitemap URL matches the exact path used by your server, confirming consistency across canonical domain settings, and validating that the sitemap index references valid, reachable sitemaps with correct relative paths.
Another frequent pitfall is misalignment between the sitemap’s declared URLs and the domain search engines crawl. If you publish a sitemap at https://example.com/sitemap.xml but robots.txt or the sitemap index references pages on http://example.org, crawlers will fail to map content correctly. Ensure the destination domain, protocol, and path are uniform across your sitemap, robots.txt, and submitted feed. For ongoing optimization, consider maintaining a simple mapping check as part of your weekly health routine, and consult our SEO Audit Service for rigorous checks on crawlability and indexability.
DNS health is the first gate for sitemap delivery. Even if the sitemap.xml exists on the origin, its visibility to crawlers depends on reliable domain resolution and correct routing through the network. For a site like sitemapcouldnotberead.com, DNS health directly gates whether the sitemap path becomes a readable entry point for search engines and how quickly updates propagate.
Key DNS failure modes to recognize include NXDOMAIN responses indicating the domain or subdomain does not exist in the zone; CNAME chains that fail to terminate at a reachable A or AAAA record; and misaligned apex (root) domain usage versus awww or non-www variant in the sitemap submission. When such misconfigurations persist, search engines may never discover the sitemap location, rendering the rest of your crawl and indexability work moot.
Beyond resolution, network reachability matters. Firewalls and peering issues can mask DNS success with subsequent blocks on the HTTP path. In practice, perform end-to-end checks by loading the sitemap URL from network segments that are geographically distant from your hosting region, using both a browser and a crawler simulation tool to confirm consistent accessibility.
Practical remediation includes aligning the DNS records with the published sitemap path, rechecking CNAME and A/AAAA mappings, and validating that the correct domain variant is consistently used. If you recently moved hosting or altered DNS providers, allow sufficient time for propagation and audit both the origin and edge layers to ensure the sitemap remains discoverable by search engines.
Hosting outages often present as DNS-like symptoms when the domain resolves but the origin host fails to respond. In these cases, coordinate with the hosting provider to confirm service status, review incident reports, and implement a rollback plan if a new deployment introduced the fault. For a structured, repeatable approach to overall site health, consider our SEO Audit Service to validate crawlability and indexability across DNS, hosting, and network layers.
To diagnose bottlenecks, run traceroute or mtr traces to measure packet loss, latency, and hops between your testing location and the sitemap host. Such traces reveal whether a network-level block, peering issue, or regional blocking rule prevents the crawler from reaching the sitemap. Document results over multiple time windows to distinguish transient congestion from persistent routing issues.
Another important angle is the interaction with CDNs. If your sitemap is cached at or near the edge, ensure the edge configuration respects origin headers and that stale caches do not present an unreachable resource. Test both origin and edge responses, and plan cache purges when you make DNS or provisioning changes that affect the sitemap path.
When all layers align but problems persist, it may be necessary to temporarily bypass the CDN to confirm the origin's behavior. If the origin serves the sitemap correctly but the edge does not, the remediation often involves cache invalidation, edge rule updates, or a policy adjustment that ensures consistent 200 OK responses for sitemap.xml across the global network.
Finally, keep in mind that some DNS or network issues manifest as intermittent 5xx or other HTTP error patterns at the HTTP layer. These events require a coordinated response: monitor uptime, correlate with deployment history, and maintain a rollback plan. A well-documented incident log makes it easier to isolate whether the problem is regional, provider- or customer-network-related, and accelerates subsequent fixes.
The message “sitemap could not be read” appears in Google Search Console when Google attempts to fetch a site’s sitemap but encounters issues that prevent it from parsing the file correctly. On sitemapcouldnotberead.com, this error can interrupt how your pages are discovered and indexed, especially for sites with complex structures, large catalogs, or frequent content changes. Understanding what this error signifies is the first step toward a reliable remediation plan that preserves organic visibility and indexing reliability.
In practical terms, “sitemap could not be read” signals that Google found the sitemap file but could not interpret it as valid XML. This is distinct from a “Couldn’t fetch” message, which indicates a connectivity issue or a server response problem at fetch time. When Google cannot read the sitemap, it may fall back to discovering URLs via on-page links or other signals, but the absence of a readable sitemap often reduces indexing efficiency, especially for large or frequently updated sites. Addressing the root cause quickly helps maintain consistent crawl coverage and indexing momentum for the key pages on your site.
For teams managing complex SEO programs or agencies supporting clients, Part 1 sets the stage for a methodical diagnostic approach. We outline common failure modes, initial validation steps, and the governance mindset needed to prevent recurrence. If you want to explore the broader governance and analytics framework that informs the rest of this series, you can browse the related resources on our blog or learn about Semalt Services for integrated optimization and governance guidance.
These categories cover the majority of read failures you’ll encounter. In Part 2, we will dive deeper into diagnosing each failure mode with concrete tests and validation steps, so you can pinpoint the exact cause and begin targeted remediation on our services platform.
After completing these checks, you’ll often discover whether the issue is a simple misconfiguration, a platform quirk, or something requiring a server-side adjustment. If you need hands-on guidance, you can reach out via our contact page for a tailored diagnostic, or consult our blog for case studies and step-by-step remedies.
Part 2 will take you through a practical workflow for validating sitemap format and XML syntax, including example checklists, recommended validators, and template artifacts that speed up remediation within the Semalt framework on Semalt Services.
Following the foundational overview of the sitemap could not be read error in Part 1, the next critical step is to verify that your sitemap is submitted under the exact domain and protocol Google Search Console has confirmed. In practice, domain-property mismatches are one of the most common triggers for read failures, because Google treats the sitemap as part of a specific property identity. On sitemapcouldnotberead.com, aligning domain, protocol, and property is essential to restore reliable crawling, indexing, and long-term visibility.
Why domain and property alignment matters: Google uses property boundaries to determine access to crawlable resources. If the sitemap URL uses https://example.com/sitemap.xml but the verified property is http://www.example.com, Google may fetch the file but apply policy differently or ignore it for indexing. This misalignment is a frequent cause of a read error even when the sitemap itself is technically valid XML.
How to approach the fix in a practical sequence:
When the domain and property are aligned, the sitemap should be readable and Google should index URLs more reliably. This adjustment often delivers the fastest return from a sitemap could not be read scenario, especially when the root cause is identity rather than syntax or server configuration. For deeper guidance, consult Google's official sitemap documentation and Semalt’s governance resources on the platform.
For additional support, reference Google’s sitemap troubleshooting guidance and Semalt’s governance-oriented resources. See Google’s sitemap help and the SEO Starter Guide for best practices, plus Semalt’s blog and services for templates and hands-on support: Google Search Console Help: Sitemaps, Google's SEO Starter Guide, Semalt Blog, and Semalt Services.
In Part 3, we will dive into practical sitemap validation workflows, including XML validators, sample sitemap indices, and template artifacts to speed up remediation within the Semalt framework on sitemapcouldnotberead.com.
With the domain and property alignment addressed in Part 2, the next practical check is to verify that the sitemap URL itself is accessible directly from a browser. This quick validation helps confirm there are no hosting, caching, or CDN quirks that would mask deeper read-or-index issues. A sitemap that refuses to load in a browser often implies an origin-server or network-layer problem rather than a malformed XML file, and it sets the stage for targeted remediation before you re-check in Google Search Console.
Use this part of the diagnostic as a baseline sanity check. If the sitemap loads with a 200 status and displays well-formed XML, you can focus on XML validity, encoding, and Google-specific indexing signals. If the page loads but presents an HTML fallback, a redirect loop, or an error page, the fix usually begins with hosting rules, caching layers, or firewall settings rather than the sitemap file itself.
If you discover any blocking rules or misconfigurations during this step, document the fixes in your governance templates and prepare a clean re-submission plan. You can also leverage related guidance on our blog and service pages to standardize remediation workflows: Semalt Blog and Semalt Services.
Even when the sitemap loads in a browser, it may still fail Google’s parsing if there are XML syntax or encoding issues. Common culprits include invalid characters, unescaped entities, mismatched tags, or non-UTF-8 encoding. Run a validator and fix any errors before re-submitting. Encoding problems, in particular, can produce unreadable results in some environments but render perfectly fine in others, so a consistent validator pass is essential.
After resolving syntax or encoding issues, re-validate the file and ensure the validator reports a clean, well-formed XML sitemap. Once validated, perform a fresh browser load and, if possible, a new fetch from the origin to confirm the issue is resolved end-to-end. For additional depth on best practices, see Google’s sitemap help and our governance resources linked below.
If your site has a large catalog or a high number of URLs, your sitemap might exceed the 50,000 URL limit or the 50 MB uncompressed size. In that case, split the content into multiple sitemap files and reference them from a sitemap index. This approach prevents read-time errors and maintains scalable crawl coverage. When using a CDN or host with aggressive caching, ensure the index and all child sitemaps are consistently served from the origin without stale copies.
After implementing a sitemap index, test each child sitemap individually in the browser, then re-submit the index to Google Search Console. If your platform automatically generates sitemaps (WordPress, Shopify, etc.), confirm that the platform’s sitemap indexing feature is up to date and that any overrides in robots.txt or CDN rules are not blocking access to the index or its children.
With the sitemap accessible and syntactically clean, re-submit to Google Search Console and use the URL Inspection tool to request indexing. Then monitor the Sitemaps report to confirm Google can access all listed URLs and that indexing momentum begins to resume. Pair this with the Coverage report to verify that no new blocks or duplications appear after the fix. Regularly review the single source of truth for your sitemap mappings to prevent future drift that could re-create read errors.
For ongoing guidance, you can explore practical references on the Semalt Blog for governance patterns and templates, or consult Semalt Services for integrated optimization and analytics capabilities. Official guidance from Google remains a pivotal reference point: Google Search Console Help: Sitemaps and Google's SEO Starter Guide.
In subsequent parts of this series, we’ll translate these practical browser checks into end-to-end remediation playbooks that cover validation, re-submission, and governance-driven reporting for sitemap health across projects on sitemapcouldnotberead.com.
Building on the ranking insights established in Parts 1–3, Part 4 translates movement in keyword positions into concrete on-page optimization actions. The goal is to close the loop between what users search for, how search engines interpret intent, and how your pages, content clusters, and internal links actually capture and sustain those signals. This section provides practical frameworks for turning rank changes into action-ready content briefs, scalable topic clusters, and an efficient internal-linking schema that accelerates execution within Semalt’s SEO framework.
Rank movements are not just numbers on a dashboard. They reveal gaps in coverage, opportunities to deepen topical authority, and pages that can be reinforced through better structure and navigation. By systematically mapping ranking shifts to on-page improvements, you create a repeatable workflow that scales with your housing of keyword families and content clusters. This approach aligns with Google’s user-first optimization principles and Semalt’s governance-focused, data-driven framework.
First, treat rank shifts as signals about content gaps. When a group of keywords moves up or down, identify whether the underlying content fully answers user intent or if related topics are missing. Use a simple diagnostic checklist to capture immediate gaps:
In practice, this means establishing a quarterly content-gap ledger tied to your keyword families. When a term moves in ranking, you audit the family holistically, not just the landing page. The ledger becomes a living document that feeds your content calendar and ensures that coverage expands in a controlled, measurable way.
Templates accelerate execution and create a consistent standard across teams. A practical content brief for a keyword family might include the following elements:
By standardizing briefs, you reduce variance in quality and speed up review cycles. Semalt’s governance approach encourages a single source of truth for keyword families and content briefs, ensuring every piece of content aligns with the hub’s purpose and the broader SEO program. For practical references on user-centric optimization and governance, consult Google’s SEO Starter Guide and Semalt’s governance resources on Semalt Blog and Semalt Services.
Topic clusters are a scalable way to organize content around user intent. A cluster consists of a hub page (the pillar) and multiple spokes (supporting pages) that answer related questions and expand coverage. When ranking data indicates rising interest in a theme, you can quickly build out new spokes to capture additional queries and reinforce topical authority.
Clusters benefit crawl efficiency and contextual relevance, signaling to search engines that your site comprehensively covers a topic. Semalt recommends aligning clusters with a content calendar and governance rituals to ensure timely updates and consistent ownership. For reference on how to align with best practices, review Google's starter guide and Semalt’s governance resources on Semalt Blog and Semalt Services.
Internal linking is a vital mechanism for distributing topical authority and guiding both users and crawlers through your content ecosystem. A well-designed linking schema ensures that priority pages accumulate authority and that new spokes quickly benefit from hub credibility.
To implement effectively, start with a mapping exercise: for each keyword family, map primary hub URLs to spokes, identify anchor text, and confirm that every new page includes at least one link back to the hub. Regularly audit linking to prevent orphaned pages and ensure a balanced distribution of link equity across the cluster. Semalt’s governance and content resources provide templates and checklists to standardize this process across teams. For practical references on user-centric optimization and governance, consult Google’s SEO Starter Guide and Semalt’s governance resources on Semalt Blog and Semalt Services.
Adopt a quarterly rhythm that pairs ranking analysis with a content-production sprint. Start with a cluster inventory, validate hub-to-spoke mappings, and identify gaps to fill. Then, execute content briefs, publish new spokes, and refresh meta data and internal links. Finally, measure impact on rankings, impressions, and on-site engagement to inform the next cycle. This cadence keeps the program durable, scalable, and tightly aligned with SEO signals that search engines reward.
Maintain a governance layer that tracks ownership, cadence, and outcomes for each content cluster. Reference Google’s user-centric optimization principles and Semalt’s governance resources to keep the program auditable, privacy-forward, and scalable across teams. Practical references include: Google's SEO Starter Guide, Semalt Blog, and Semalt Services.
Part 5 will translate these content-optimization templates into a concrete, hands-on workflow for operationalizing rank-tracking insights. We’ll cover tooling integration, governance playbooks, and a sample weekly plan that bridges data collection with live content execution on Semalt Services.
O erro "Sitemap could not be read" impede que o Google rastreie seu site corretamente
Quando o Google exibe este erro no Search Console, significa que seus robôs não conseguiram processar seu arquivo sitemap. Este problema crítico impede que o Google descubra e indexe suas páginas.
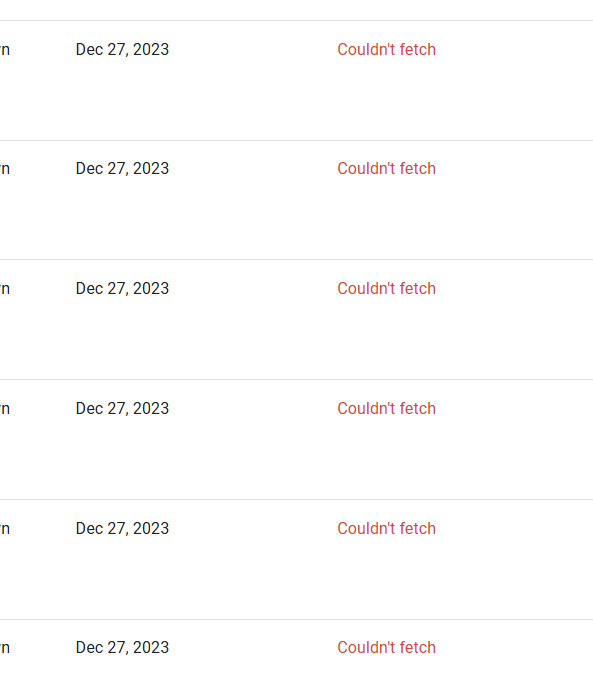
Compreender as causas ajudará você a encontrar a solução certa
Muitas URLs para o Google processar efetivamente
GoogleBot tem cotas por site que se esgotam rapidamente
Timeouts ou erros ao recuperar o sitemap
Estrutura XML inválida ou excedendo limites
IndexJump usa tecnologia avançada para garantir a indexação de suas páginas
Comece com um teste gratuito - sem cartão de crédito